
01 Nov AWS launches its next-gen GPU instances
AWS today announced the launch of its newest GPU-equipped instances. Dubbed P4, these new instances are launching a decade after AWS launched its first set of Cluster GPU instances. This new generation is powered by Intel Cascade Lake processors and eight of NVIDIA’s A100 Tensor Core GPUs. These instances, AWS promises, offer up to 2.5x the deep learning performance of the previous generation — and training a comparable model should be about 60% cheaper with these new instances.
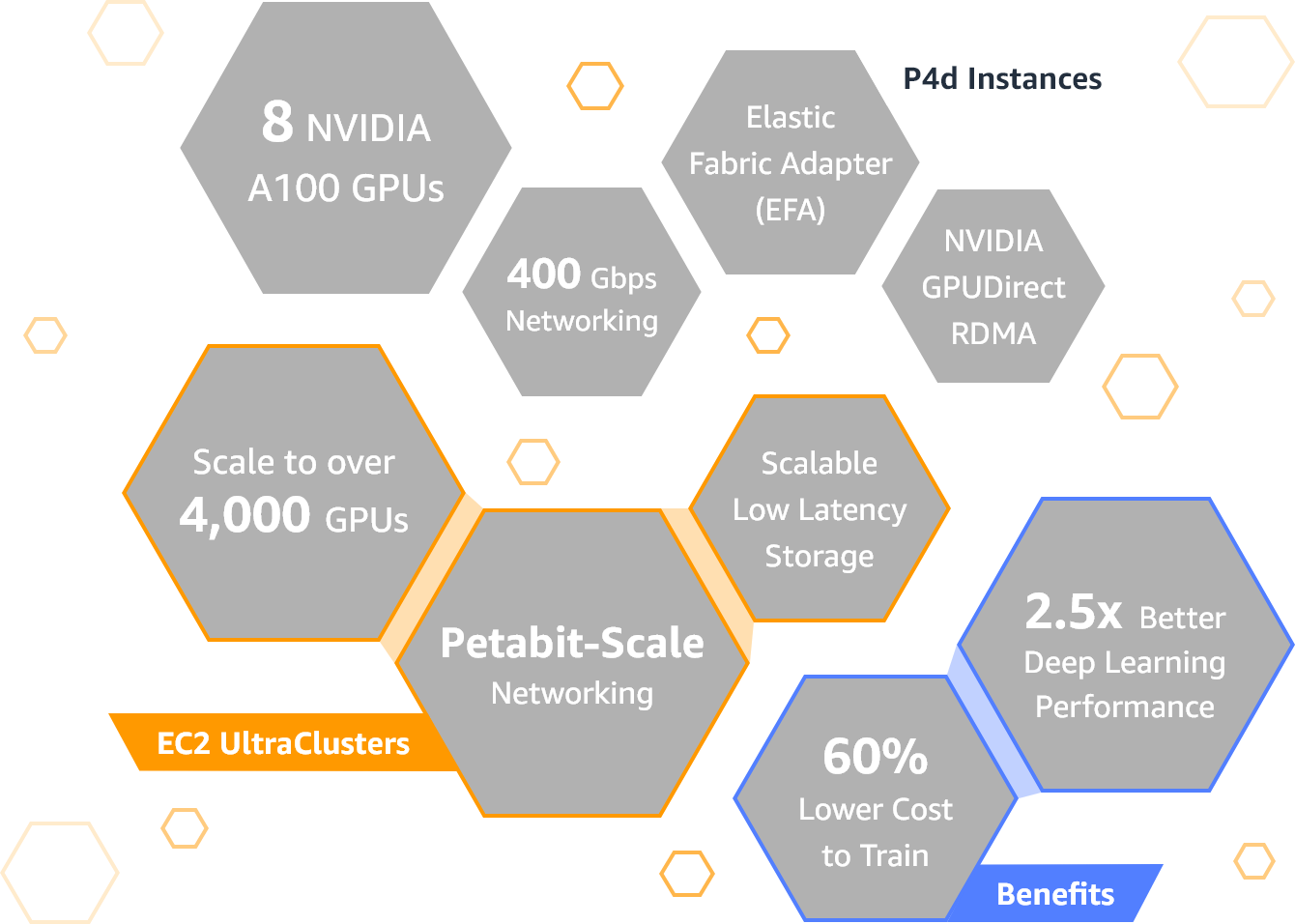
Image Credits: AWS
For now, there is only one size available, the p4d.12xlarge instance, in AWS slang and the eight A100 GPUs are connected over NVIDIA’s NVLink communication interface and offer support for the company’s GPUDirect interface as well.
With 320 GB of high-bandwidth GPU memory and 400 Gbps networking, this is obviously a very powerful machine. Add to that the 96 CPU cores, 1.1 TB of system memory and 8 TB of SSD storage and it’s maybe no surprise that the on-demand price is $32.77 per hour (though that price goes down to less than $20/hour for 1-year reserved instances and $11.57 for three-year reserved ones.

Image Credits: AWS
On the extreme end, you can combine 4,000 or more GPUs into an EC2 UltraCluster, as AWS calls these machines, for high-performance computing workloads at what is essentially a supercomputer-scale machine. Given the price, you’re not likely to spin up one of these clusters to train your a model for your toy app anytime soon, but AWS has already been working with a number of enterprise customers to test these instances and clusters, including Toyota Research Institute, GE Healthcare and Aon.
“At [Toyota Research Institute], we’re working to build a future where everyone has the freedom to move,” said Mike Garrison, Technical Lead, Infrastructure Engineering at TRI. “The previous generation P3 instances helped us reduce our time to train machine learning models from days to hours and we are looking forward to utilizing P4d instances, as the additional GPU memory and more efficient float formats will allow our machine learning team to train with more complex models at an even faster speed.”
Sorry, the comment form is closed at this time.