
05 May Crawler Traps: Causes, Solutions & Prevention – A Developer’s Deep Dive by @hamletbatista
In past articles, I’ve written about how programming skills can help you diagnose and solve complex problems, blend data from different sources, and even automate your SEO work.
In this article, we are going to leverage the programming skills we’ve been building to learn by doing/coding.
Specifically, we are going to take a close look at one of the most impactful technical SEO problems you can solve: identifying and removing crawler traps.
We are going to explore a number of examples – their causes, solutions through HTML and Python code snippets.
Plus, we’ll do something even more interesting: write a simple crawler that can avoid crawler traps and that only takes 10 lines of Python code!
My goal with this column is that once you deeply understand what causes crawler traps, you can not just solve them after the fact, but assist developers in preventing them from happening in the first place.
A Primer on Crawler Traps
A crawler trap happens when a search engine crawler or SEO spider starts grabbing a large number of URLs that don’t result in new unique content or links.
The problem with crawler traps is that they eat up the crawl budget the search engines allocate per site.
Once the budget is exhausted, the search engine won’t have time to crawl the actual valuable pages from the site. This can result in significant loss of traffic.
This is a common problem on database driven sites because most developers don’t even know this is a serious problem.
When they evaluate a site from an end user perspective, it operates fine and they don’t see any issues. That is because end users are selective when clicking on links, they don’t follow every link on a page.
How a Crawler Works
Let’s look at how a crawler navigates a site by finding and following links in the HTML code.
Below is the code for a simple example of a Scrapy based crawler. I adapted it from the code on their home page. Feel free to follow their tutorial to learn more about building custom crawlers.
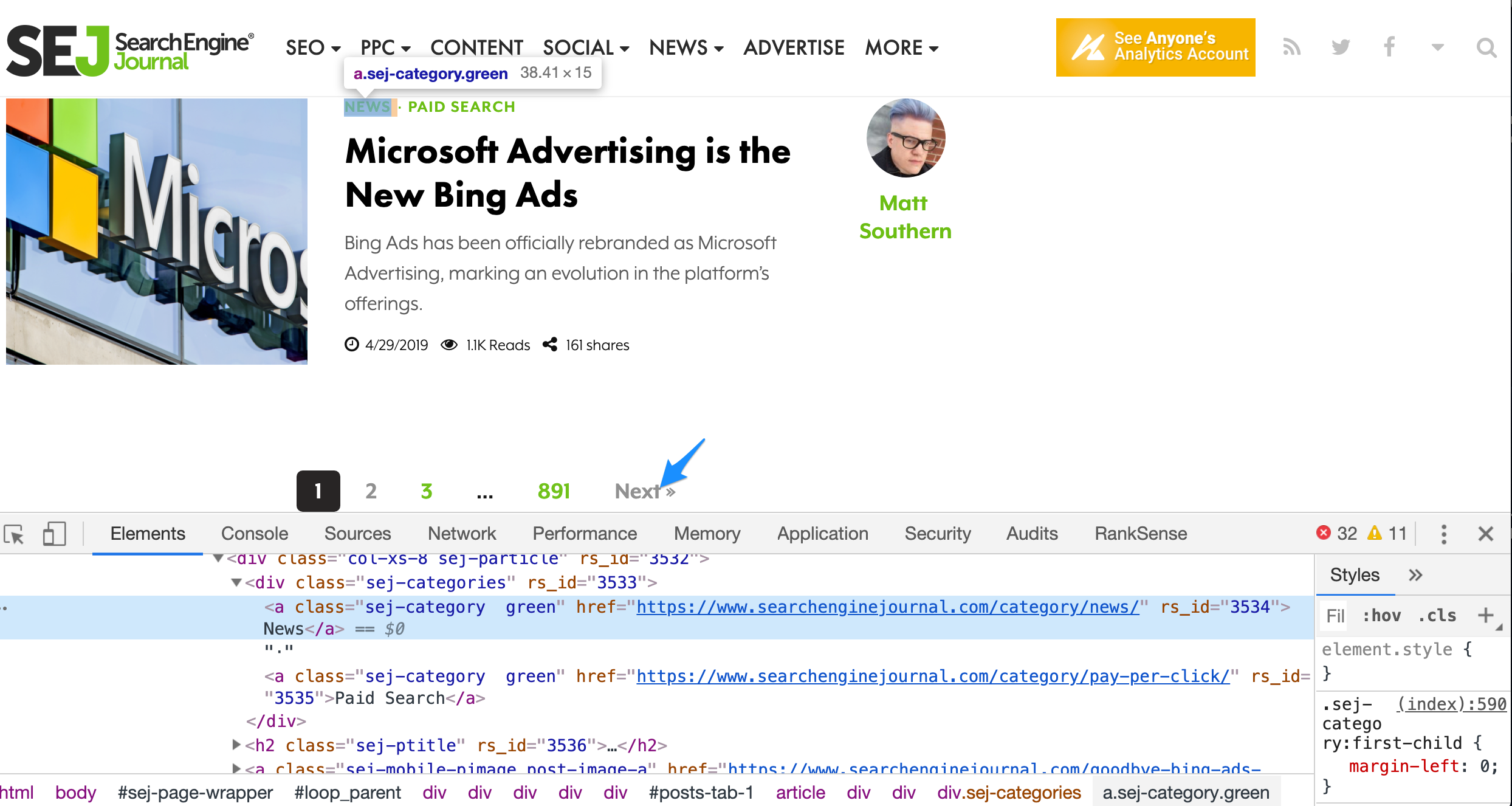
The first for loop grabs all article blocks from the Latest Posts section, and the second loop only follows the Next link I’m highlighting with an arrow.
When you write a selective crawler like this, you can easily skip most crawler traps!
You can save the code to a local file and run the spider from the command line, like this:
$scrapy runspider sejspider.py
Or from a script or jupyter notebook.
Here is the example log of the crawler run:
Traditional crawlers extract and follow all links from the page. Some links will be relative, some absolute, some will lead to other sites, and most will lead to other pages within the site.
The crawler needs to make relative URLs absolute before crawling them, and mark which ones have been visited to avoid visiting again.
A search engine crawler is a bit more complicated than this. It is designed as a distributed crawler. This means the crawls to your site don’t come from one machine/IP but from several.
This topic is outside of the scope of this article, but you can read the Scrapy documentation to learn about how to implement one and get an even deeper perspective.
Now that you have seen crawler code and understand how it works, let’s explore some common crawler traps and see why a crawler would fall for them.
How a Crawler Falls for Traps
I compiled a list of some common (and not so common) cases from my own experience, Google’s documentation and some articles from the community that I link in the resources section. Feel free to check them out to get the bigger picture.
A common and incorrect solution to crawler traps is adding meta robots noindex or canonicals to the duplicate pages. This won’t work because this doesn’t reduce the crawling space. The pages still need to be crawled. This is one example of why it is important to understand how things work at a fundamental level.
Session Identifiers
Nowadays, most websites using HTTP cookies to identify users and if they turn off their cookies they prevent them from using the site.
But, many sites still use an alternative approach to identify users: the session ID. This ID is unique per website visitor and it is automatically embedded to all URLs of page.
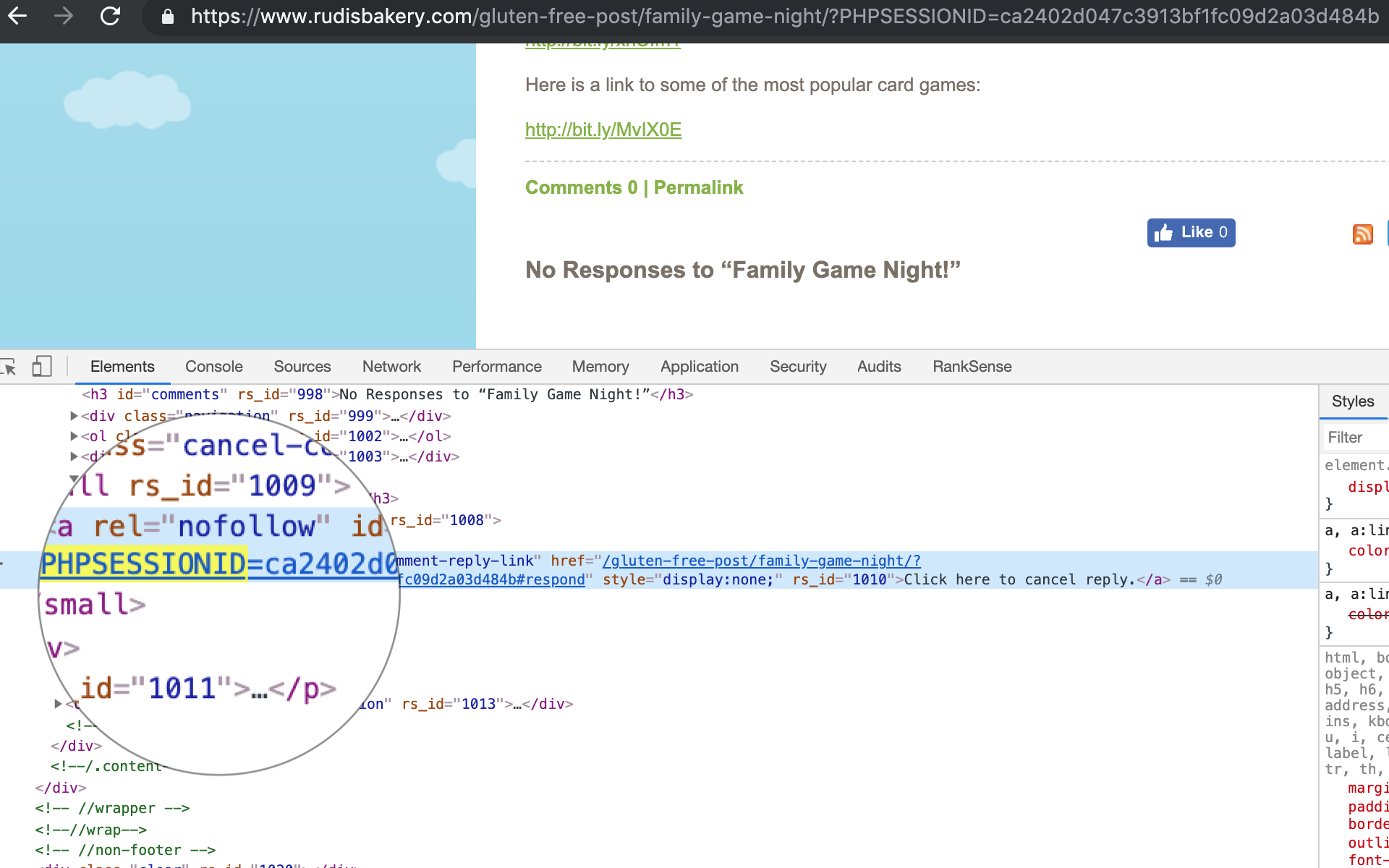
When a search engine crawler crawls the page, all the URLs will have the session ID, which makes the URLs unique and seemingly with new content.
But, remember that search engine crawlers are distributed, so the requests will come from different IPs. This leads to even more unique session IDs.
We want search crawlers to crawl:
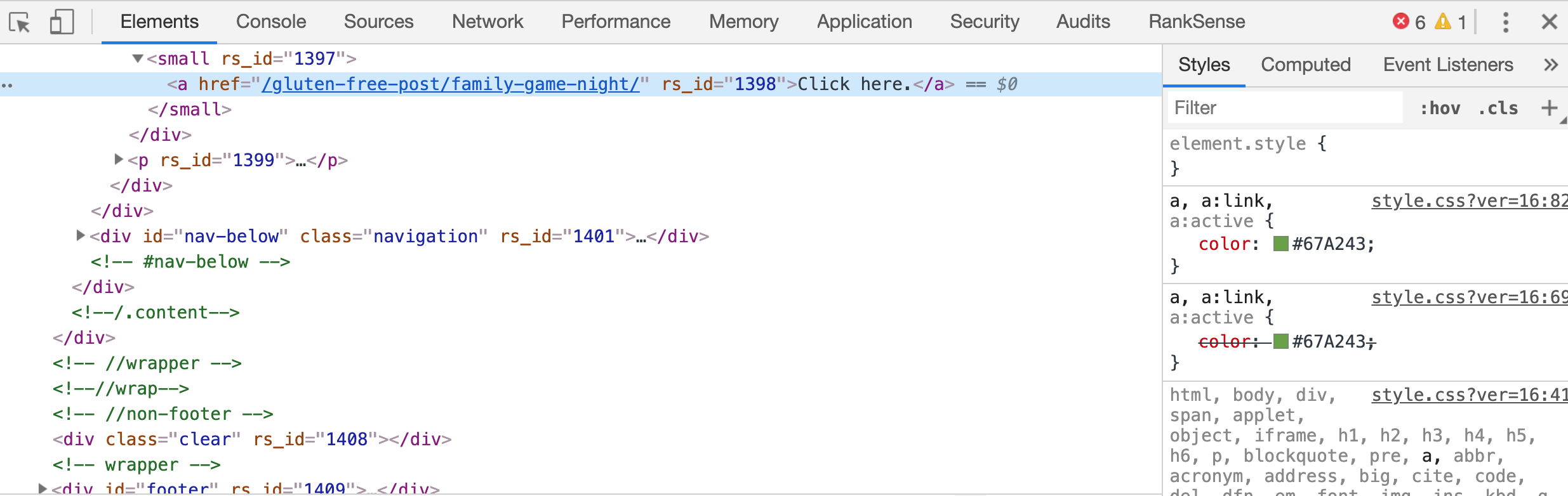
But they crawl:
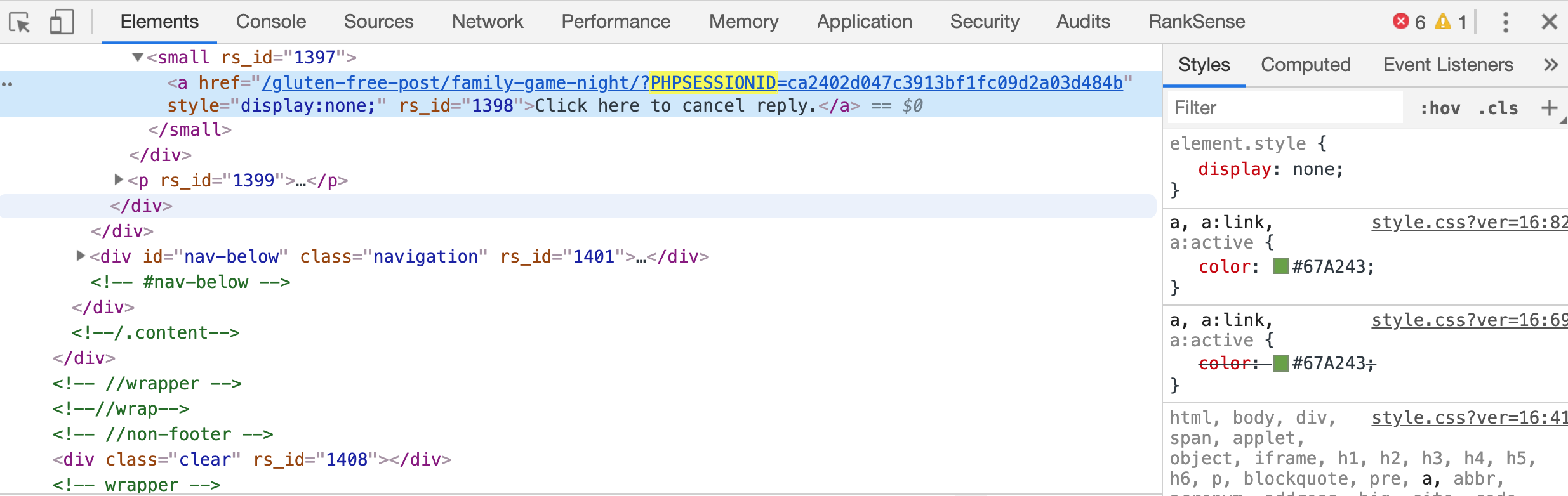
When the session ID is a URL parameter, this is an easy problem to solve because you can block it in the URL parameters settings.
But, what if the session ID is embedded in the actual path of the URLs? Yes, that is possible and valid.
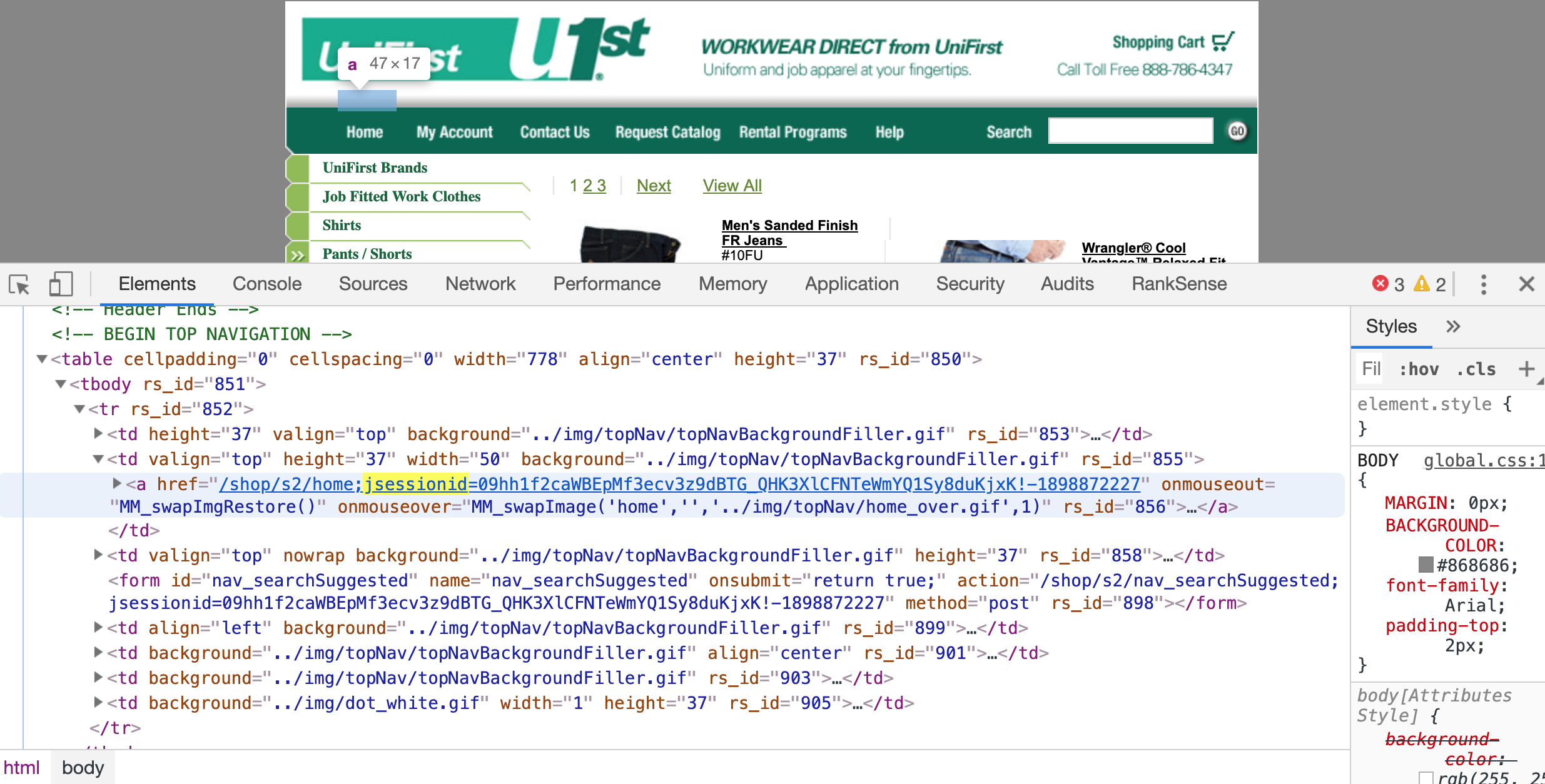
Web servers based on the Enterprise Java Beans spec, used to append the session ID in the path like this: ;jsessionid. You can easily find sites still getting indexed with this in their URLs.
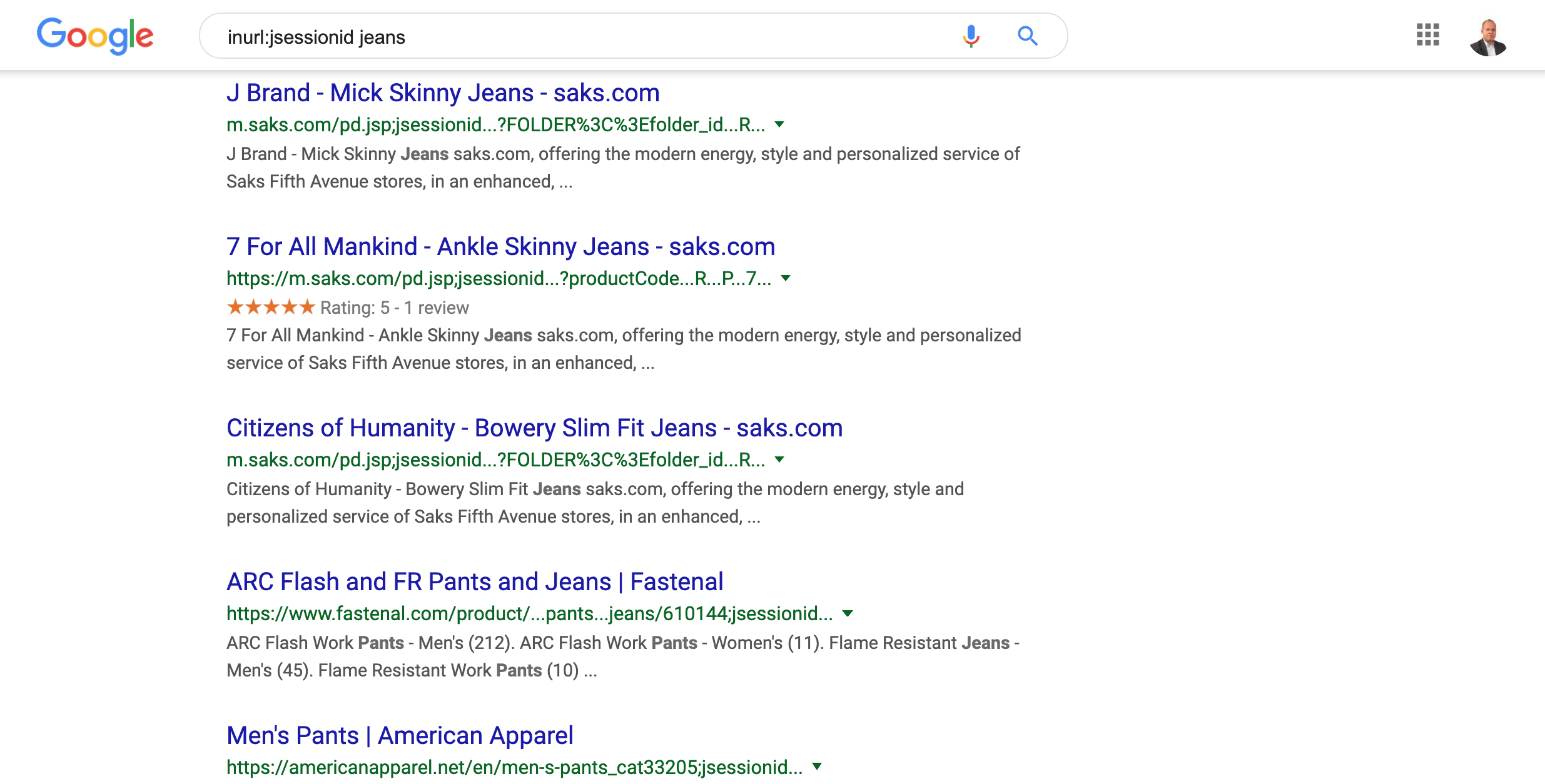
It is not possible to block this parameter when included in the path. You need to fix it at the source.
Now, if you are writing your own crawler, you can easily skip this with this code 😉
Faceted navigation
Faceted or guided navigations, which are super common on ecommerce websites, are probably the most common source of crawler traps on modern sites.
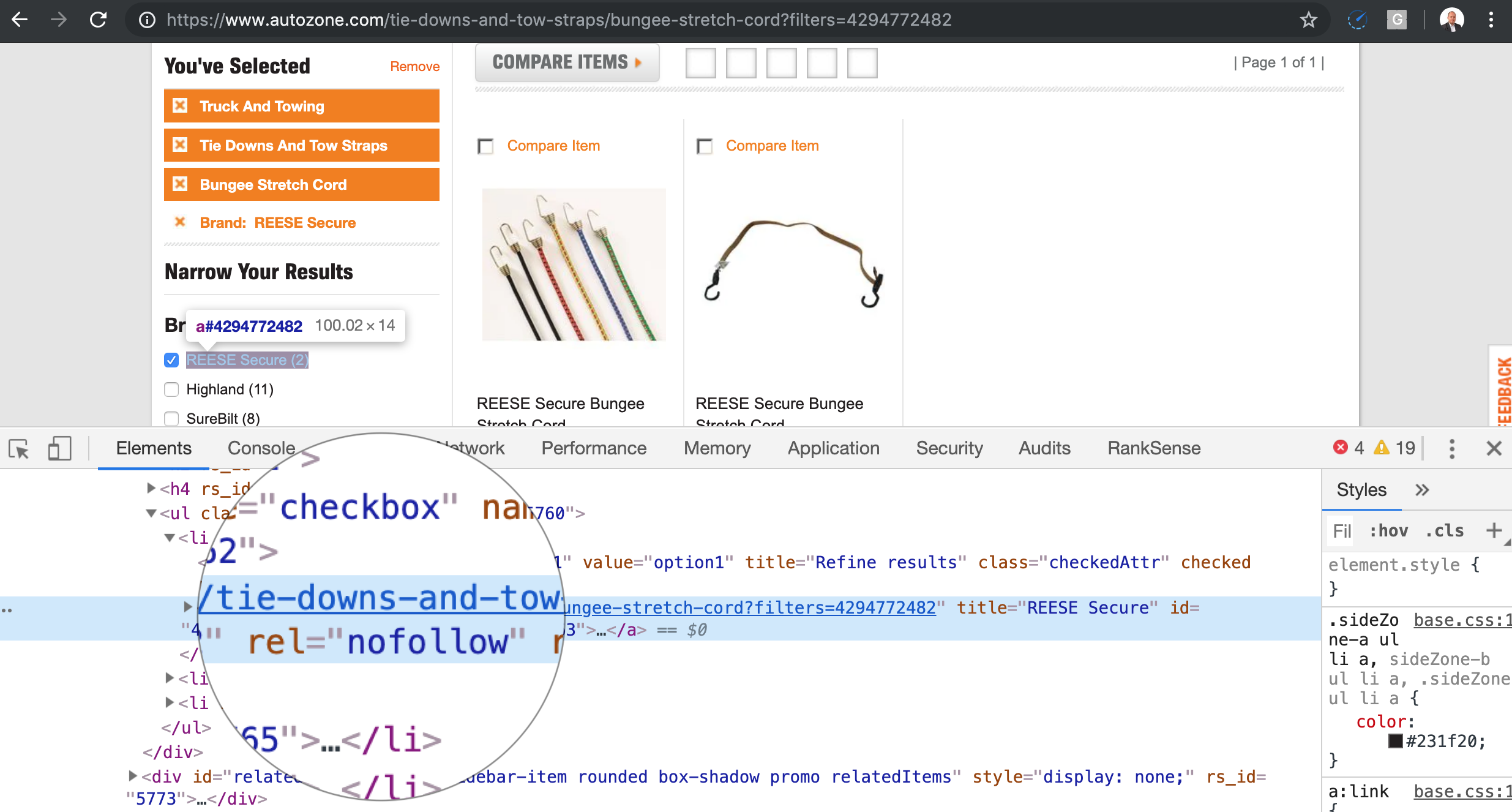
The problem is that a regular user only makes a few selections, but when we instruct our crawler to grab these links and follow them, it will try every possible permutation. The number of URLs to crawl becomes a combinatorial problem. In the screen above, we have X number of possible permutations.
Traditionally, you would generate these using JavaScript, but as Google can execute and crawl them, it is not enough.
A better approach is to add the parameters as URL fragments. Search engine crawlers ignore URL fragments. So the above snippet would be rewritten like this.
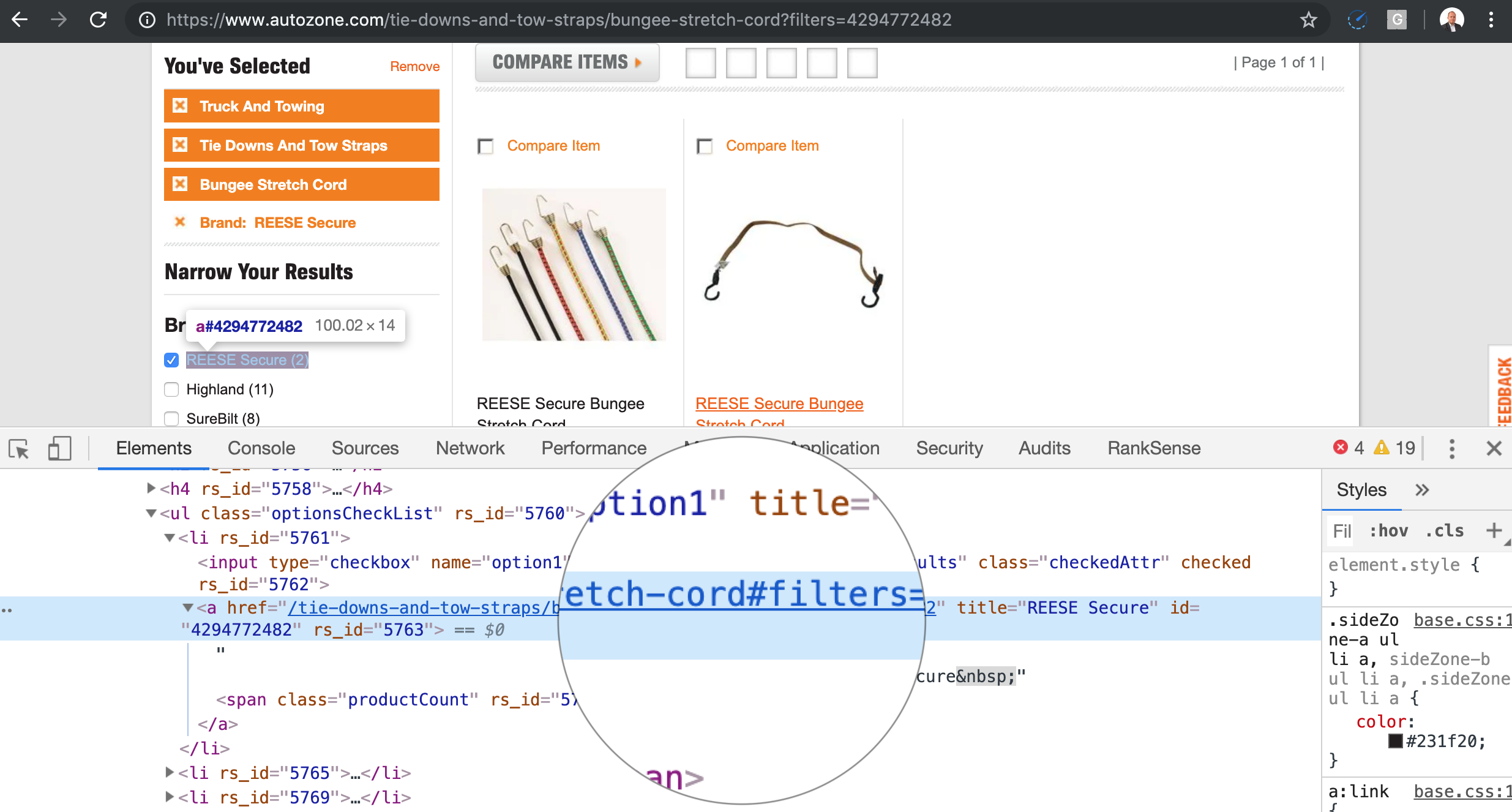
Here is the code to convert specific parameters to fragments.
One terrible faceted navigation implementation we often see converts filtering URL parameters into paths which makes any filtering by query string almost impossible.
For example, instead of /category?color=blue, you get /category/color=blue/.
Faulty Relative Links
I used to see so many problems with relative URLs, that I recommended clients always make all the URLs absolute. I later realized it was an extreme measure, but let me show with code why relative links can cause so many crawler traps.
As I mentioned, when a crawler finds relative links, it needs to convert them to absolute. In order to convert them to absolute, it uses the source URL for reference.
Here is the code to convert a relative link to absolute.
Now, see what happens when the relative link is formatted incorrectly.
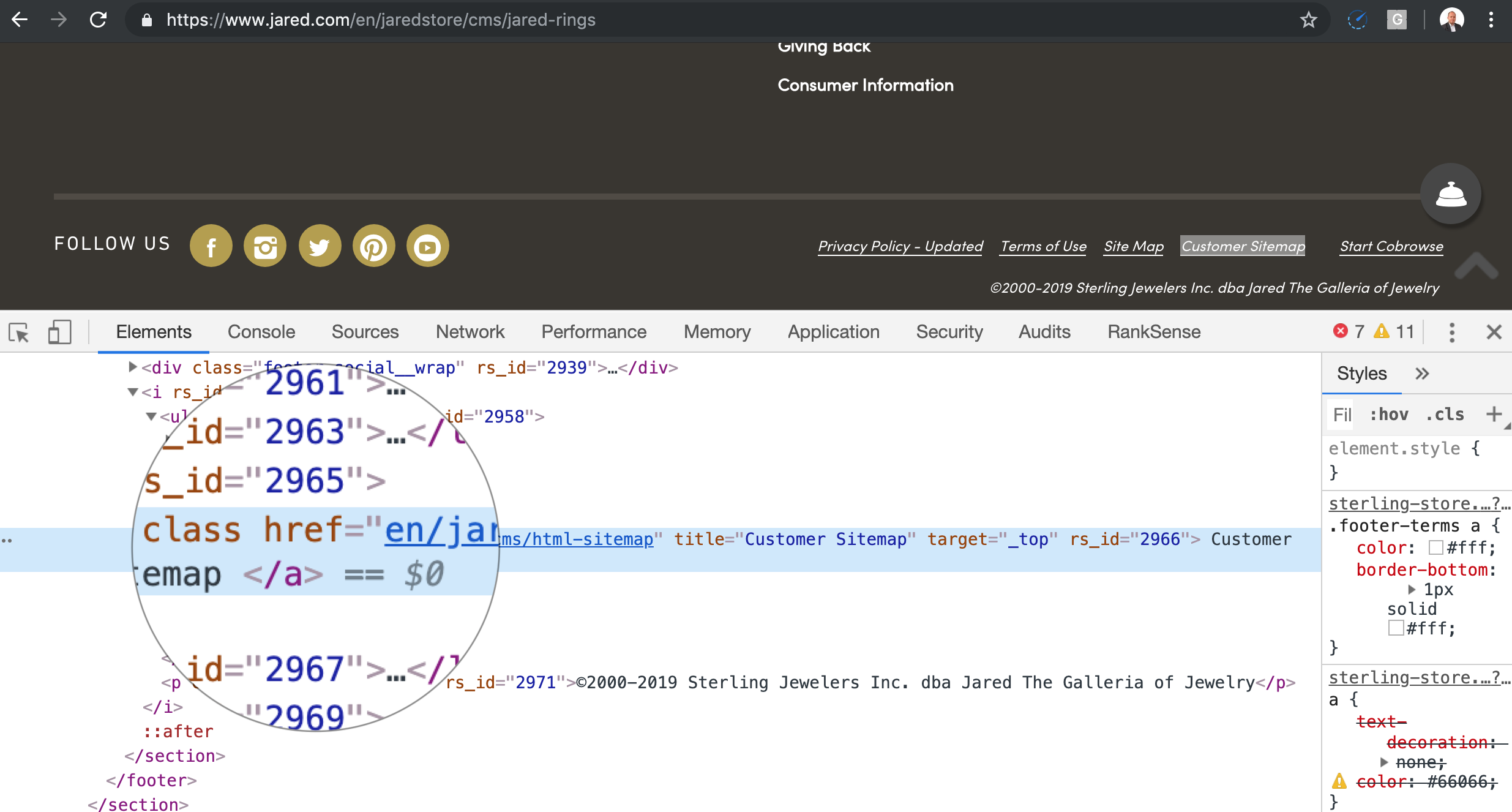
Here is the code that shows the absolute link that results.
Now, here is where the crawler trap takes place. When I open this fake URL in the browser, I don’t get a 404, which would let the crawler know to drop the page and not follow any links on it. I am getting a soft 404, which sets the trap in motion.
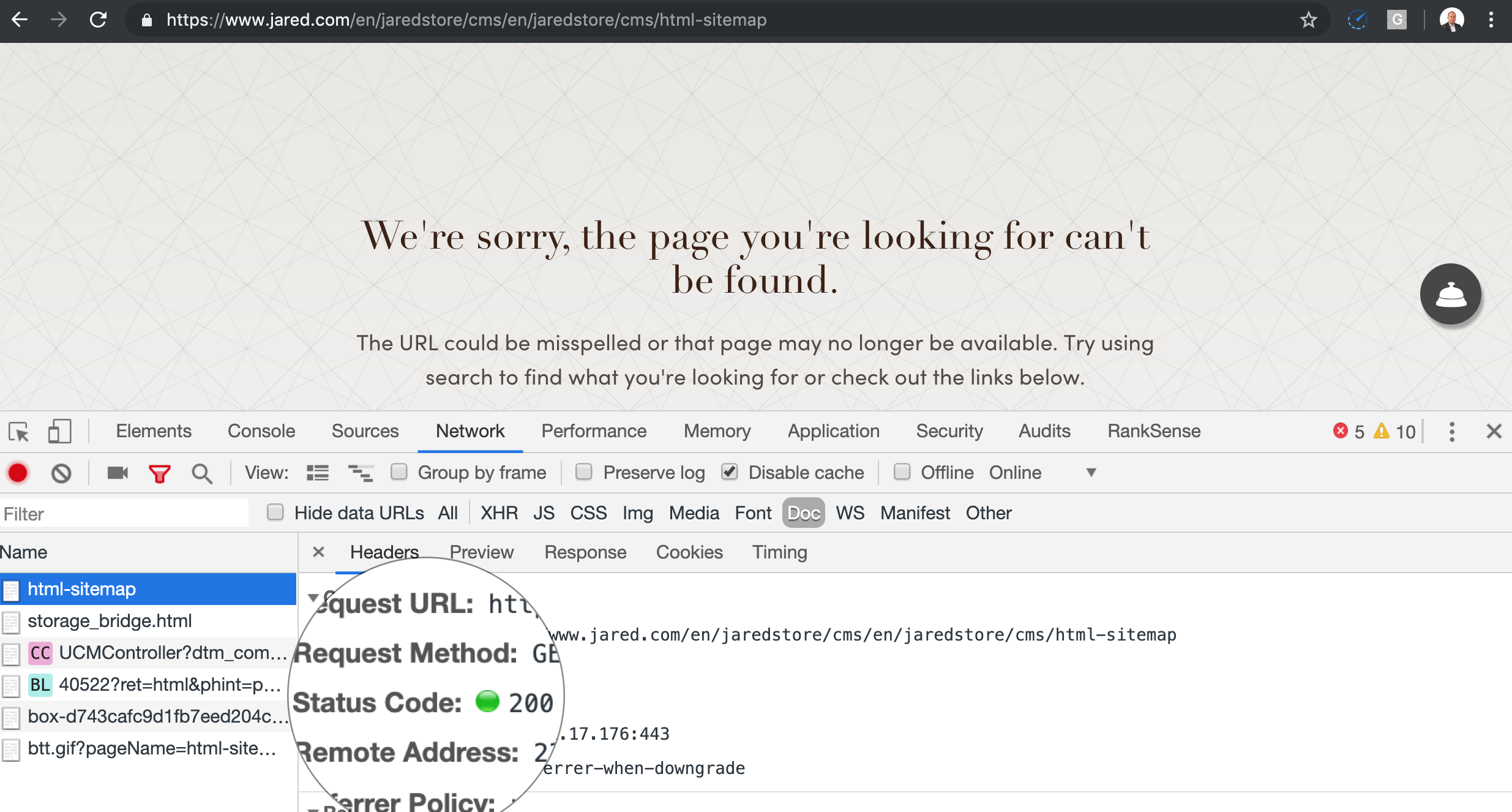
Our faulty link in the footer will grow again when the crawler tries to make an absolute URL.
The crawler will continue with this process and the fake URL will continue to grow until it hits the maximum URL limit supported by the web server software or CDN. This changes by the system.
For example, IIS and Internet Explorer don’t support URLs longer than 2,048-2,083 characters in length.
There is a fast and easy or long and painful way to catch this type of crawler trap.
You are probably already familiar with the long and painful approach: run an SEO spider for hours until it hits the trap.
You typically know it found one because it ran out of memory if you ran it on your desktop machine, or it found millions of URLs on a small site if you are using a cloud-based one.
The quick and easy way is to look for the presence of 414 status code error in the server logs. Most W3C-compliant web servers will return a 414 when URL requested is longer than it can take.
If the web server does not report 414s, you can alternatively measure the length of the requested URLs in the log, and filter any ones above 2,000 characters.
Here is the code to do either one.
Here is a variation of the missing trailing slash that is particularly difficult to detect. It happens when you copy and paste and code to word processors and they replace the quoting character.
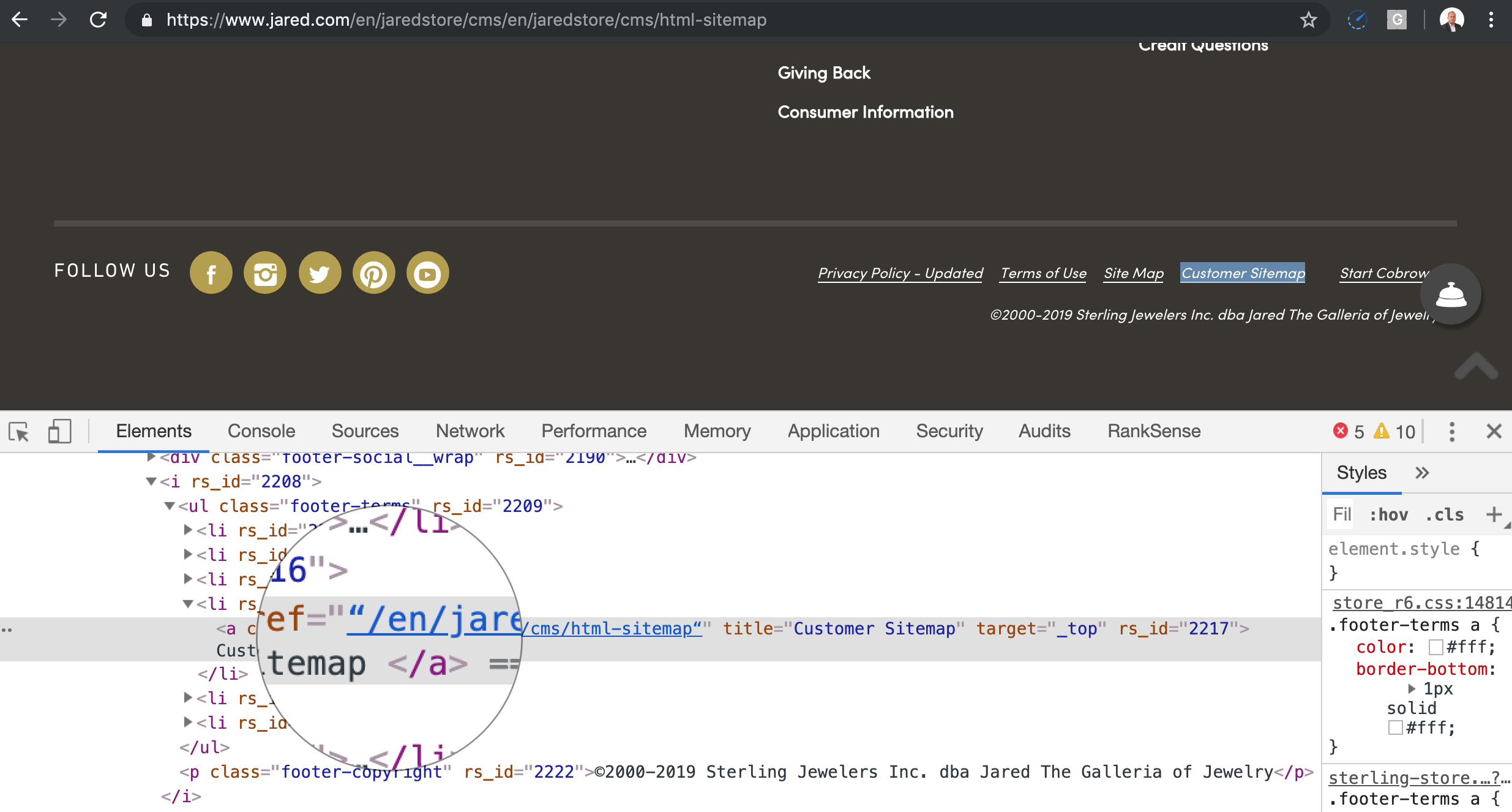
To the human eye, the quotes look the same unless you pay close attention. Let’s see what happens when the crawler converts this, apparently correct relative URL to absolute.
Cache Busting
Cache busting is a technique used by developers to force CDNs (Content Delivery Networks) to use the latest version of their hosted files.
The technique requires adding a unique identifier to the pages or page resources you want to “bust” through the CDN cache.
When developers use one or more unique identifier values, it creates additional URLs to crawl, generally images, CSS, and JavaScript files, but this is generally not a big deal.
The biggest problem happens when they decide to use random unique identifiers, update pages and resources frequently, and let the search engines crawl all variations of the files.
Here is what it looks like.
You can detect these issues in your server logs and I will cover the code to do this in the next section.
Versioned Page Caching With Image Resizing
Similar to cache busting, a curious problem occurs with static page caching plugins like one developed by a company called MageWorx.
For one of our clients, their Magento plugin was saving different versions of page resources for every change the client made.
This issue was compounded when the plugin automatically resized images to different sizes per device supported.
This was probably not a problem when they originally developed the plugin because Google was not trying to aggressively crawl page resources.
The issue is that search engine crawlers now also crawl page resources, and will crawl all versions created by the caching plugin.
We had a client where the crawl rate what 100 times the size of the site, and 70% of the crawl requests were hitting images. You can only detect an issue like this by looking at the logs.
We are going to generate fake Googlebot requests to random cached images to better illustrate the problem and so we can learn how to identify the issue.
Here is the initialization code:
Here is the loop to generate the fake log entries.
Next, let’s use pandas and matplotlib to identify this issue.
This plot displays the image below.
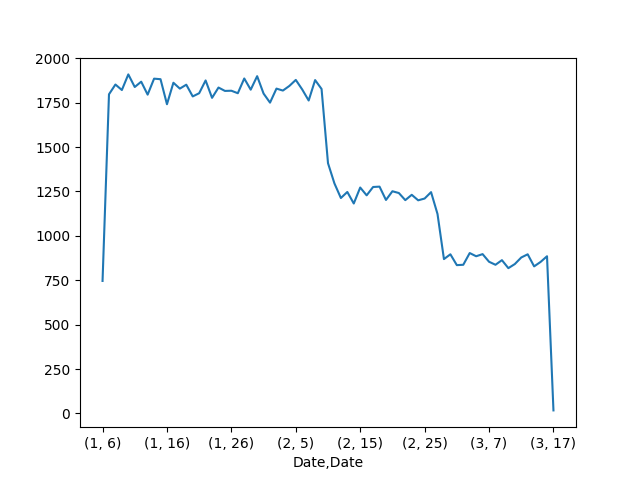
This plot shows Googlebot requests per day. It is similar to the Crawl Stats feature in the old Search Console. This report was what prompted us to dig deeper into the logs.
After you have the Googlebot requests in a Pandas data frame, it is fairly easy to pinpoint the problem.
Here is how we can filter to one of the days with the crawl spike, and break down by page type by file extension.
Long Redirect Chains & Loops
A simple way to waste crawler budget is to have really long redirect chains, or even loops. They generally happen because of coding errors.
Let’s code one example redirect chain that results in a loop in order to understand them better.
This is what happens when you open the first URL in Chrome.
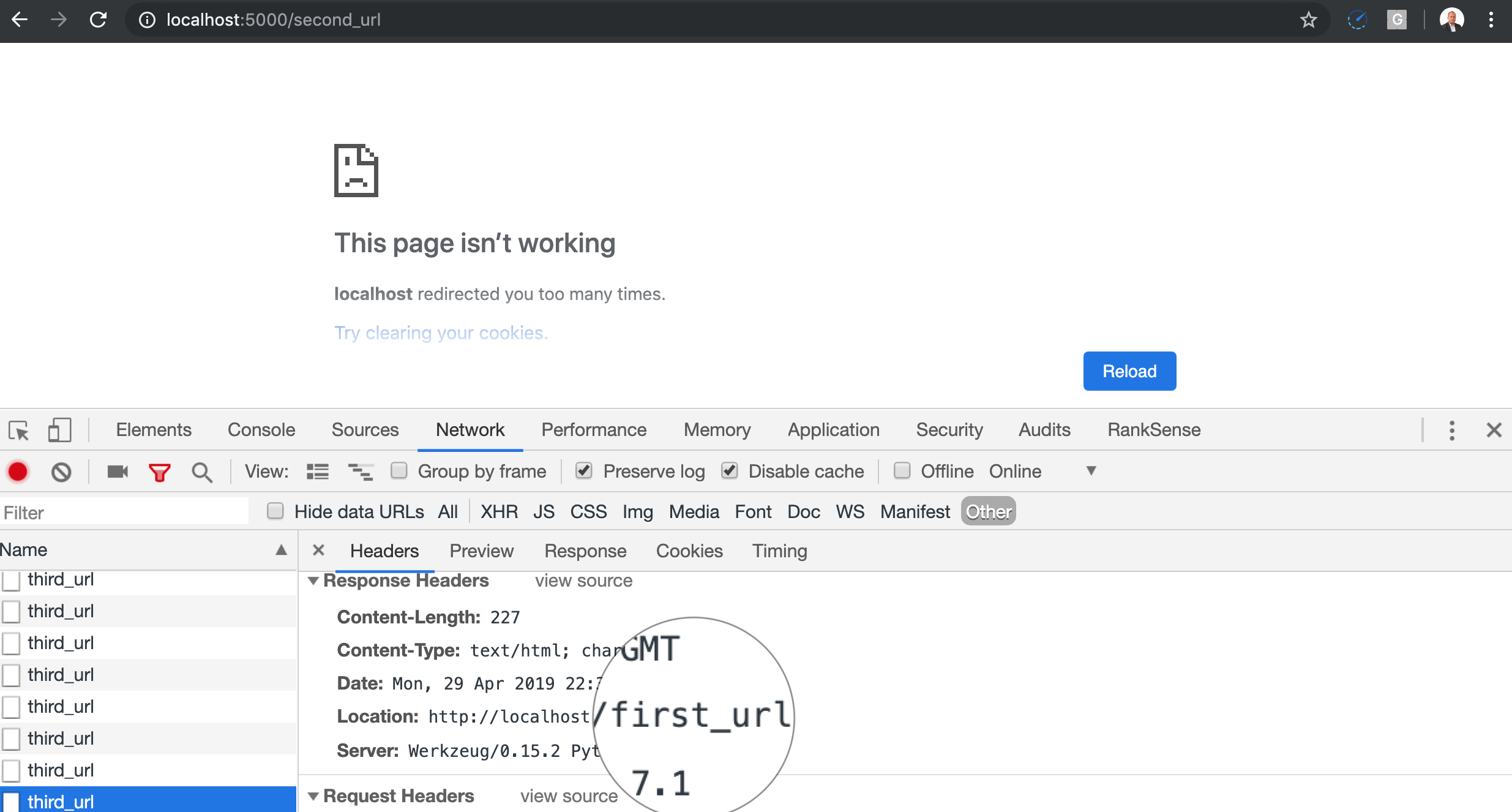
You can also see the chain in the web app log
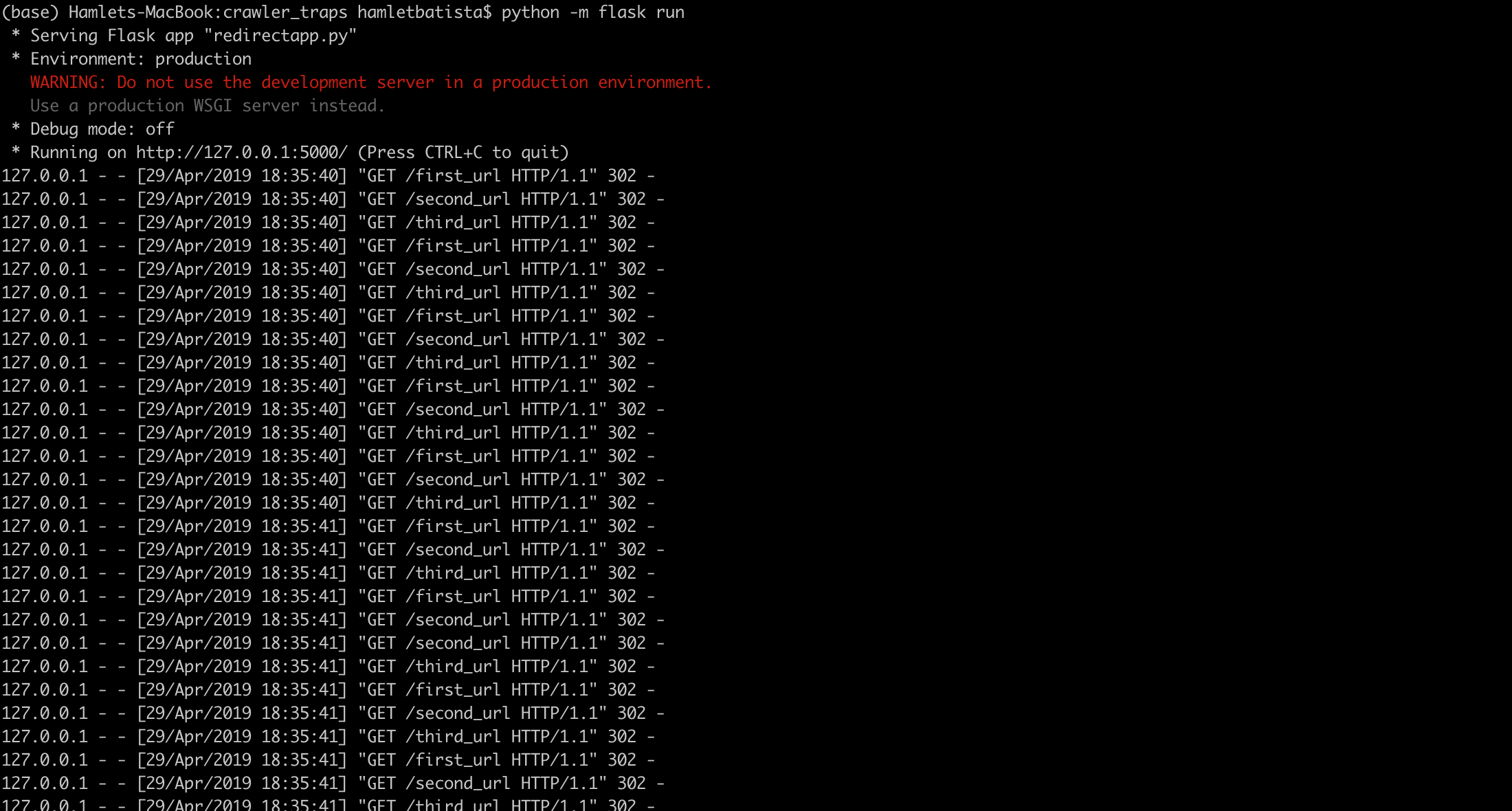
When you ask developers to implement rewrite rules to:
- Change from http to https.
- Lower case mixed case URLs.
- Make URLs search engine friendly.
- Etc.
They cascade every rule so that each one requires a separate redirect instead of a single one from source to destination.
Redirect chains are easy to detect, as you can see the code below.
They are also relatively easy to fix once you identify the problematic code. Always redirect from the source to the final destination.
Mobile/Desktop Redirect Link
An interesting type of redirect is the one used by some sites to help users force the mobile or desktop version of the site. Sometimes it uses a URL parameter to indicate the version of the site requested and this is generally a safe approach.
However, cookies and user agent detection are also popular and that is when loops can happen because search engine crawlers don’t set cookies.
This code shows how it should work correctly.
This one shows how it could work incorrectly by altering the default values to reflect wrong assumptions (dependency on the presence of HTTP cookies).
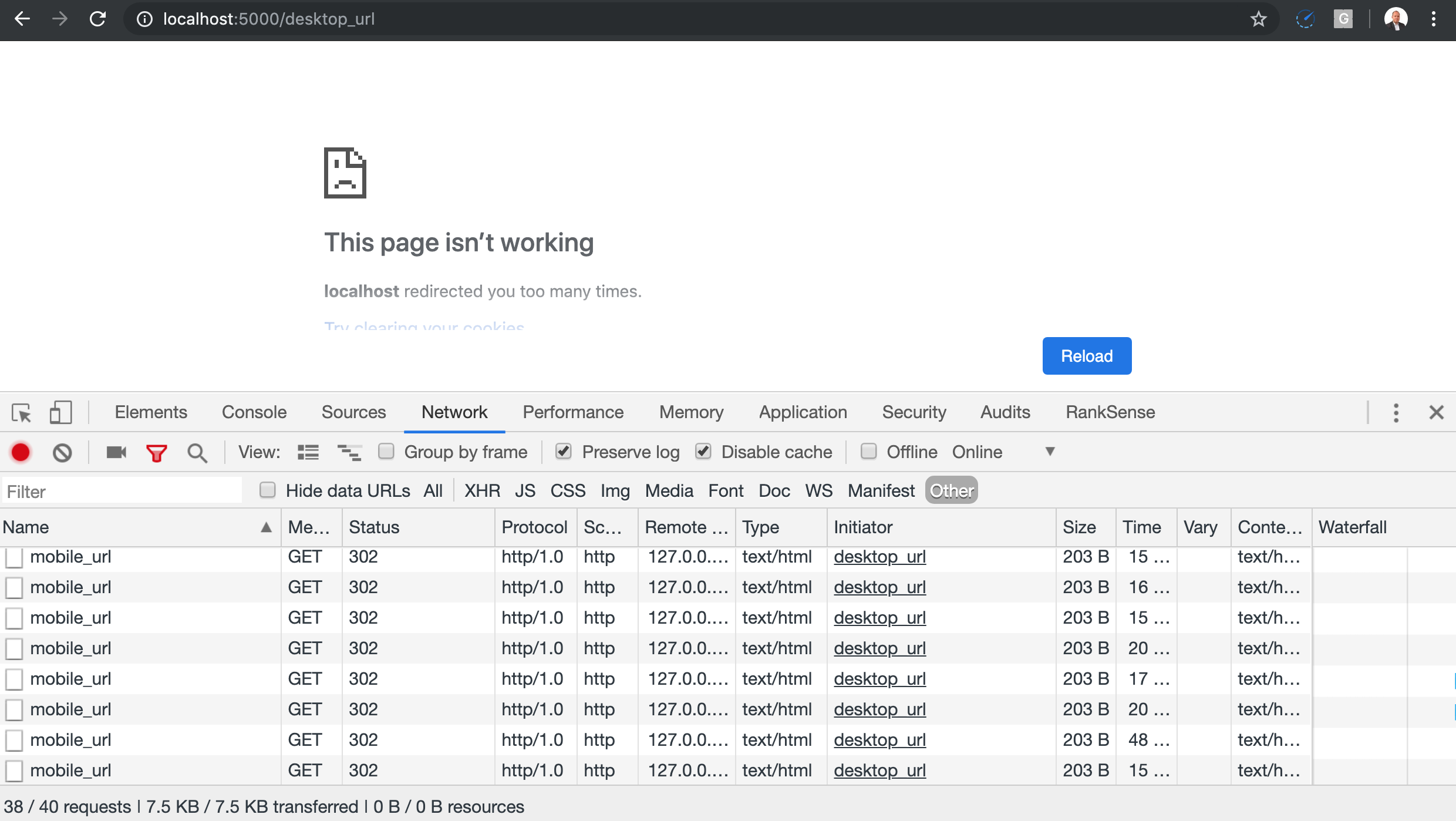
Circular Proxied URLs
This happened to us recently. It is an unusual case, but I expect this to happen more often as more services move behind proxy services like Cloudflare.
You could have URLs that are proxied multiple times in a way that they create a chain. Similar to how it happens with redirects.
You can think of proxied URLs as URLs that redirect on the server side. The URL doesn’t change in the browser but the content does. In order to see track proxied URL loops, you need to check your server logs.
We have an app in Cloudflare that makes API calls to our backend to get SEO changes to make. Our team recently introduced an error that caused our API calls to be proxied to themselves resulting in a nasty, hard to detect loop.
We used the super handy Logflare app from @chasers to review our API call logs in real-time. This is what regular calls look like.
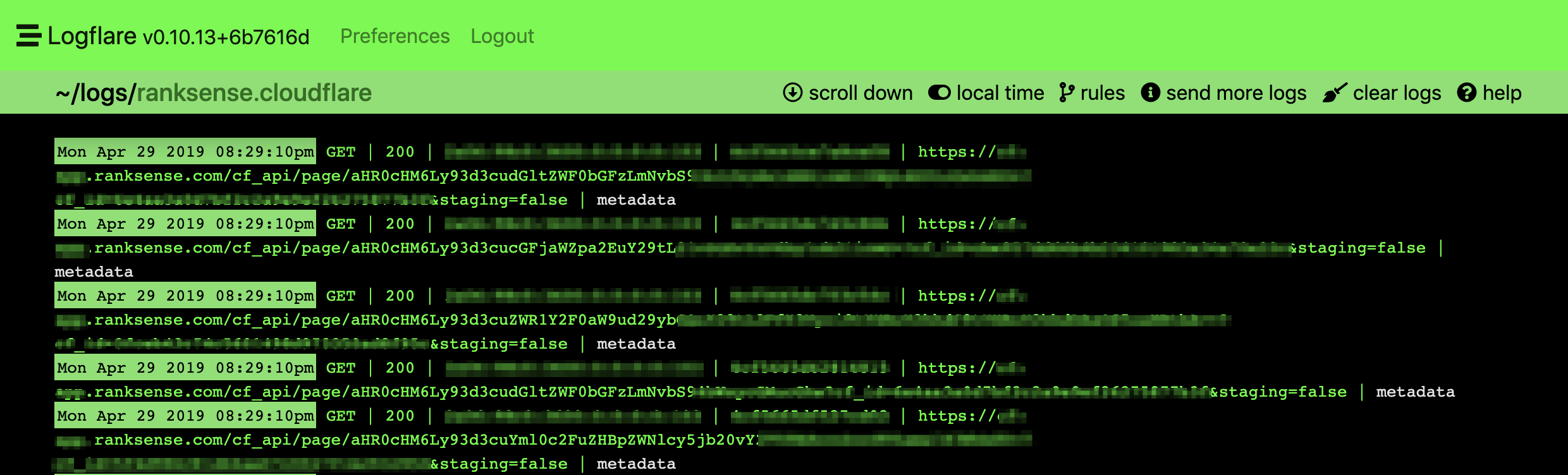
Here is an example of a circular/recursive one looks like. It is a massive request. I found hundreds of chained requests when I decoded the text.
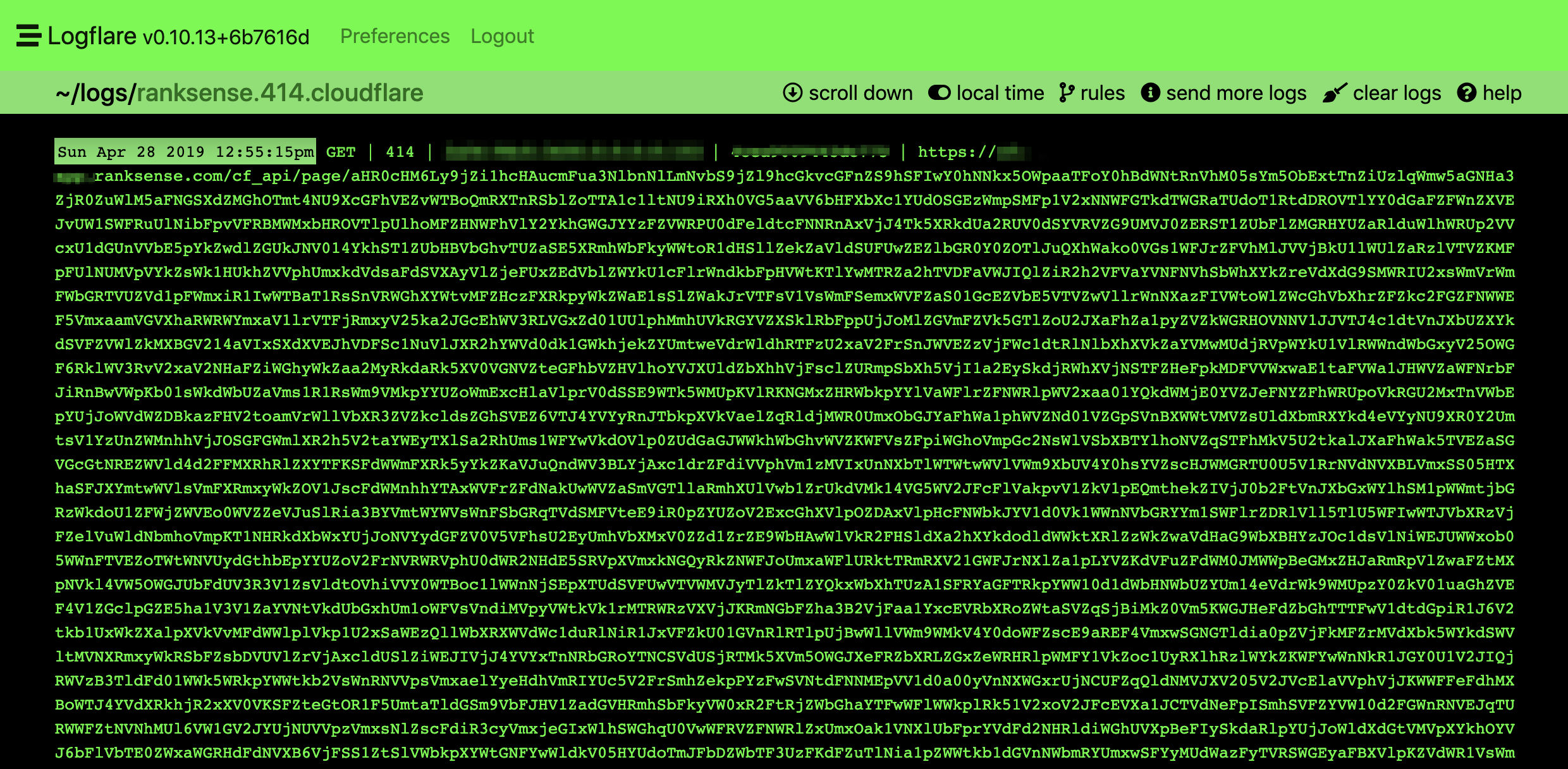
We can use the same trick we used to detect faulty relative links. We can filter by status code 414 or even the request length.
Most requests shouldn’t be longer than 2,049 characters. You can refer to the code we used for faulty redirects.
Magic URLs + Random Text
Another example, is when URLs include optional text and only require an ID to serve the content.
Generally, this is not a big deal, except when the URLs can be linked with any random, inconsistent text from within the site.
For example, when the product URL changes name often, search engines need to crawl all the variations.
Here is one example.
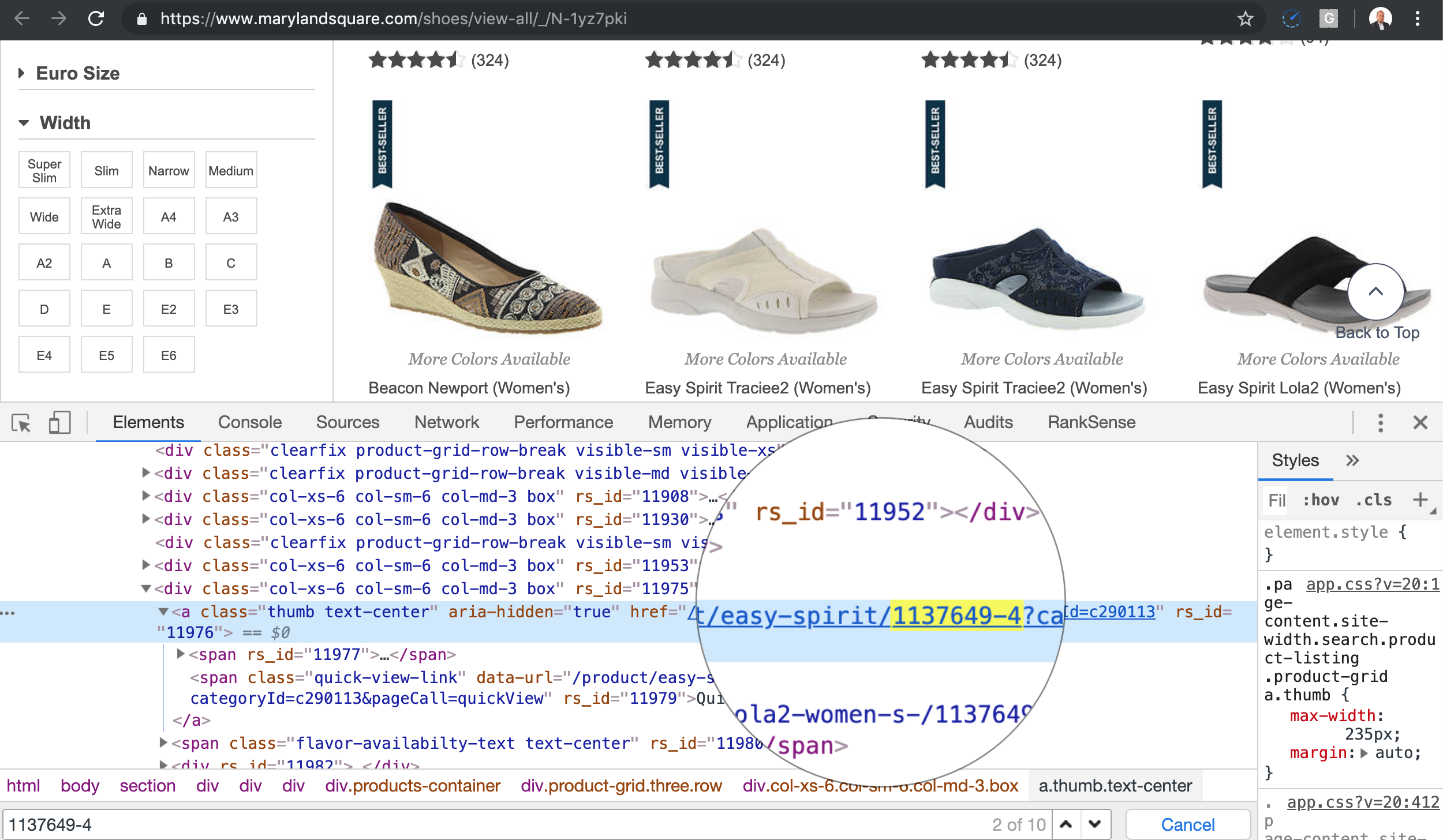
If I follow the link to the product 1137649-4 with a short text as the product description, I get the product page to load.
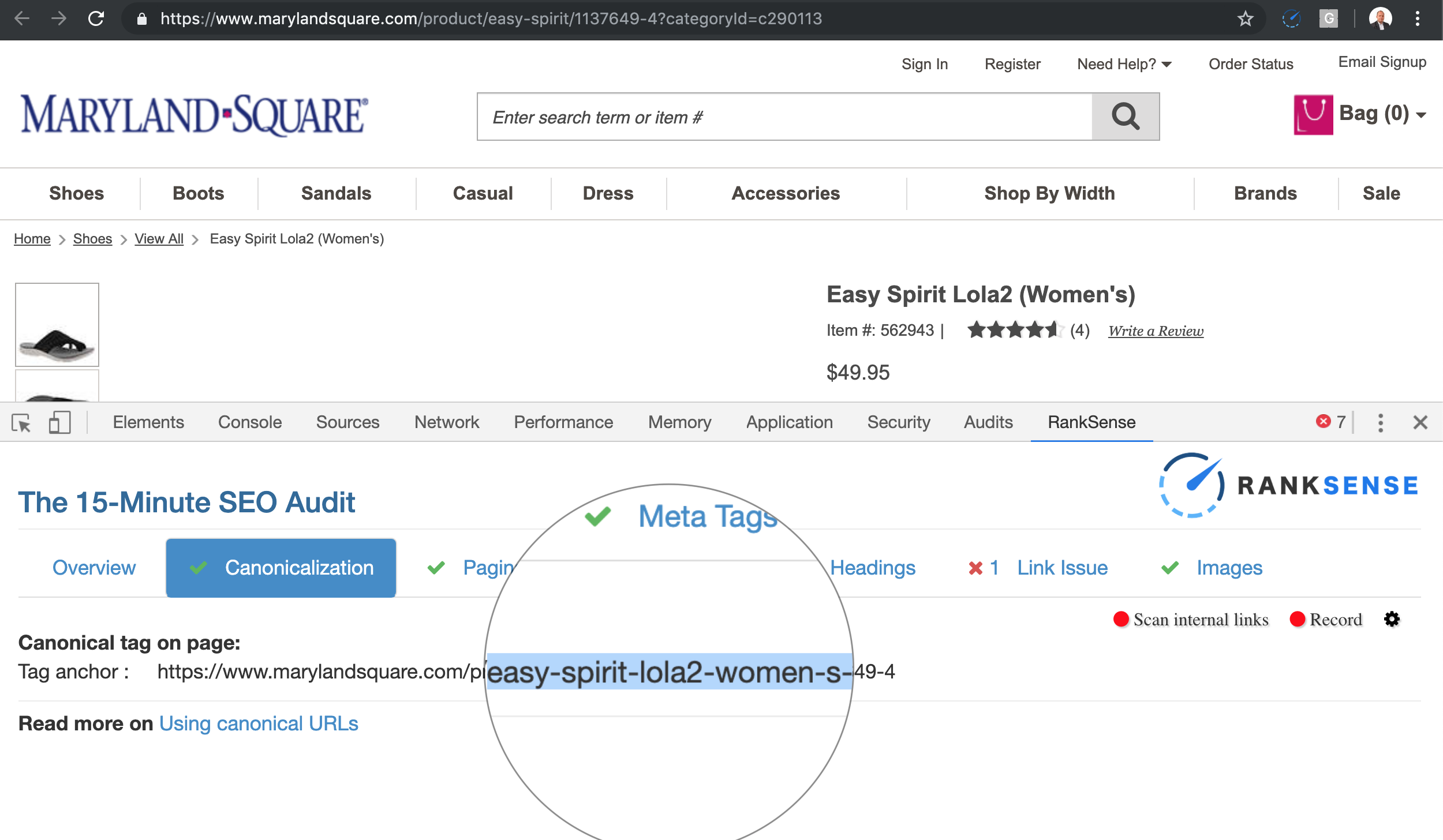
But, you can see the canonical is different than the page I requested.
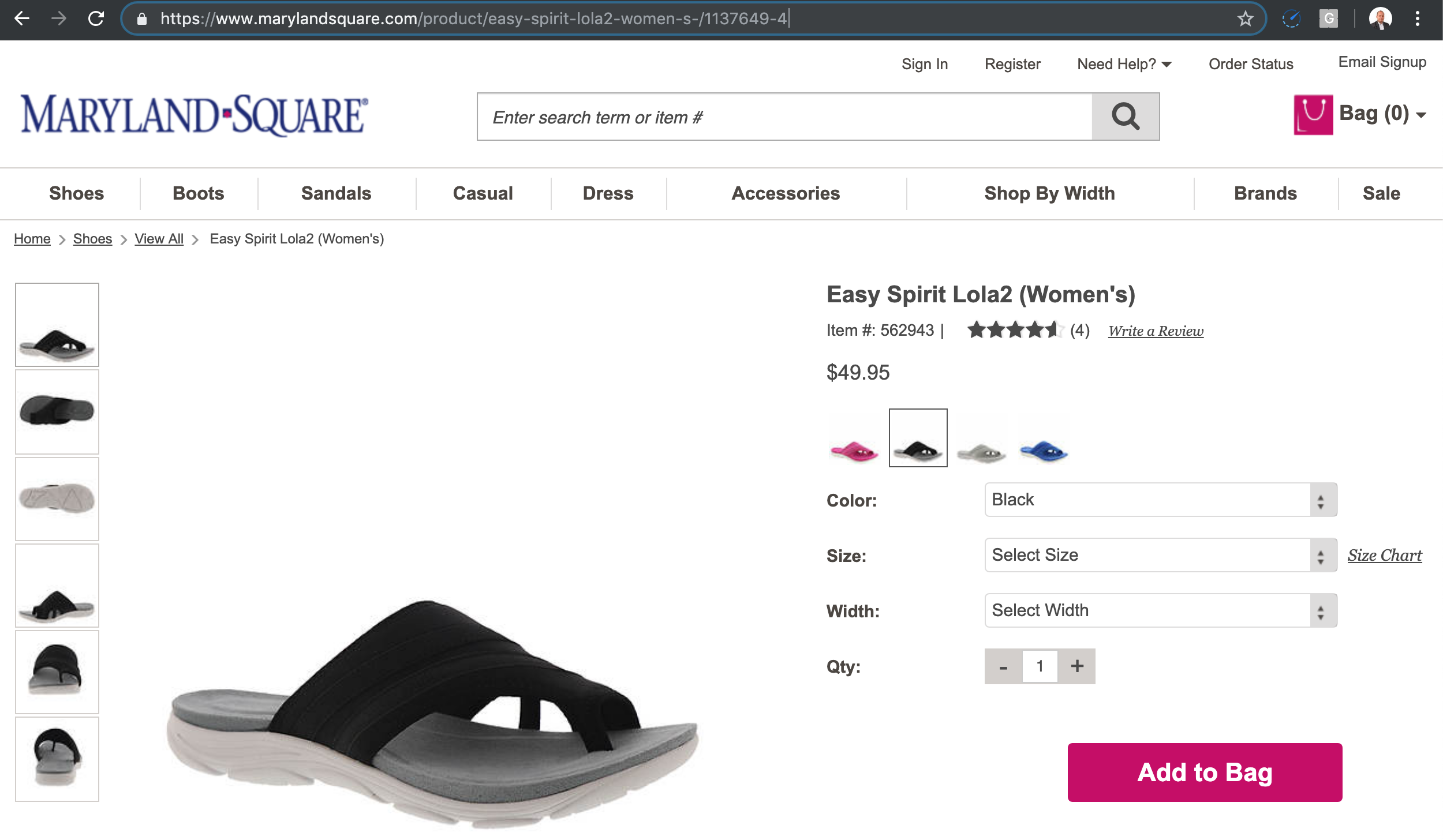
Basically, you can type any text between the product and the product ID, and the same page loads.
The canonicals fix the duplicate content issue, but the crawl space can be big depending on how many times the product name is updated.
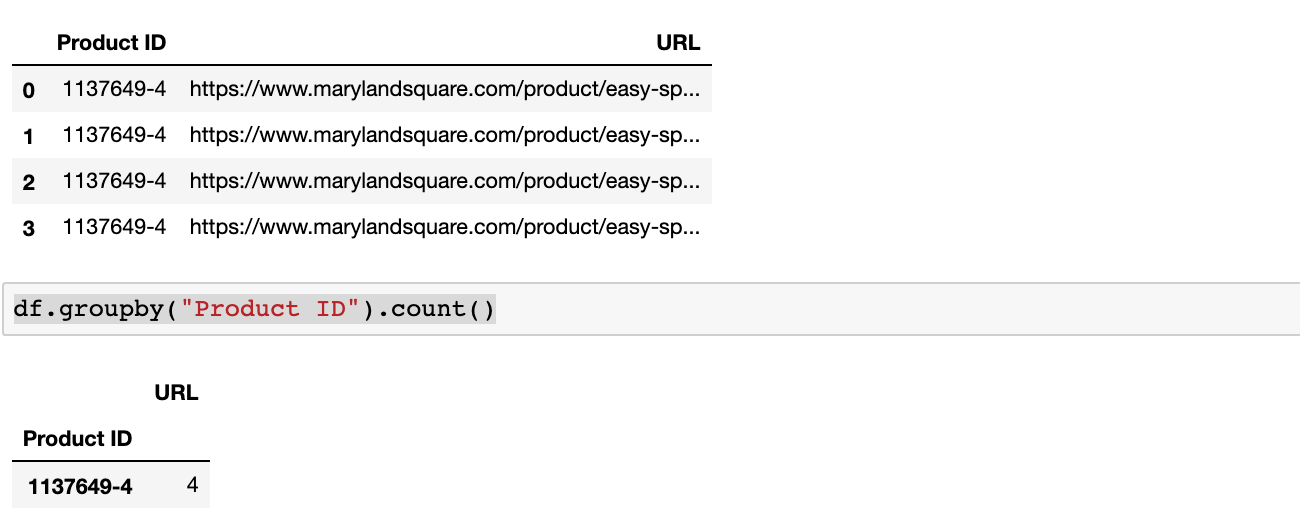
In order to track the impact of this issue, you need to break the URL paths into directories and group the URLs by their product ID. Here is the code to do that.
Here is the example output.
Links to Dynamically Generated Internal Searches
Some on-site search vendors help create “new” keyword based content simply by performing searches with a large number of keywords and formatting the search URLs like regular URLs.
A small number of such URLs is generally not a big deal, but when you combine this with massive keyword lists, you end up with a similar situation as the one I mentioned for the faceted navigation.
Too many URLs leading to mostly the same content.
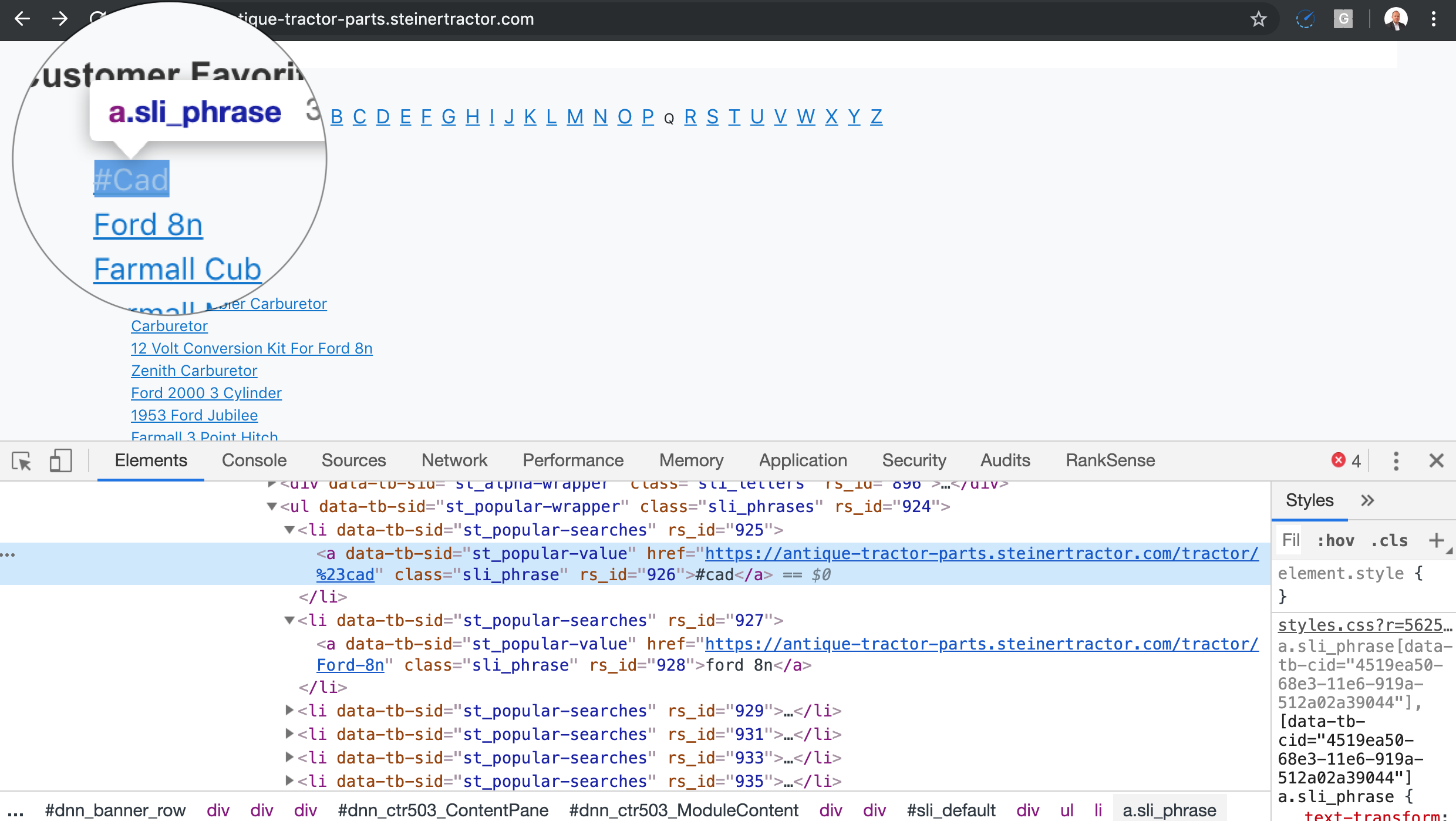
One trick you can use to detect these is to look for the class IDs of the listings and see if they match the ones of the listings when you perform a regular search.
In the example above, I see a class ID “sli_phrase”, which hints the site is using SLI Systems to power their search.
I’ll leave the code to detect this one as an exercise for the reader.
Calendar/Event Links
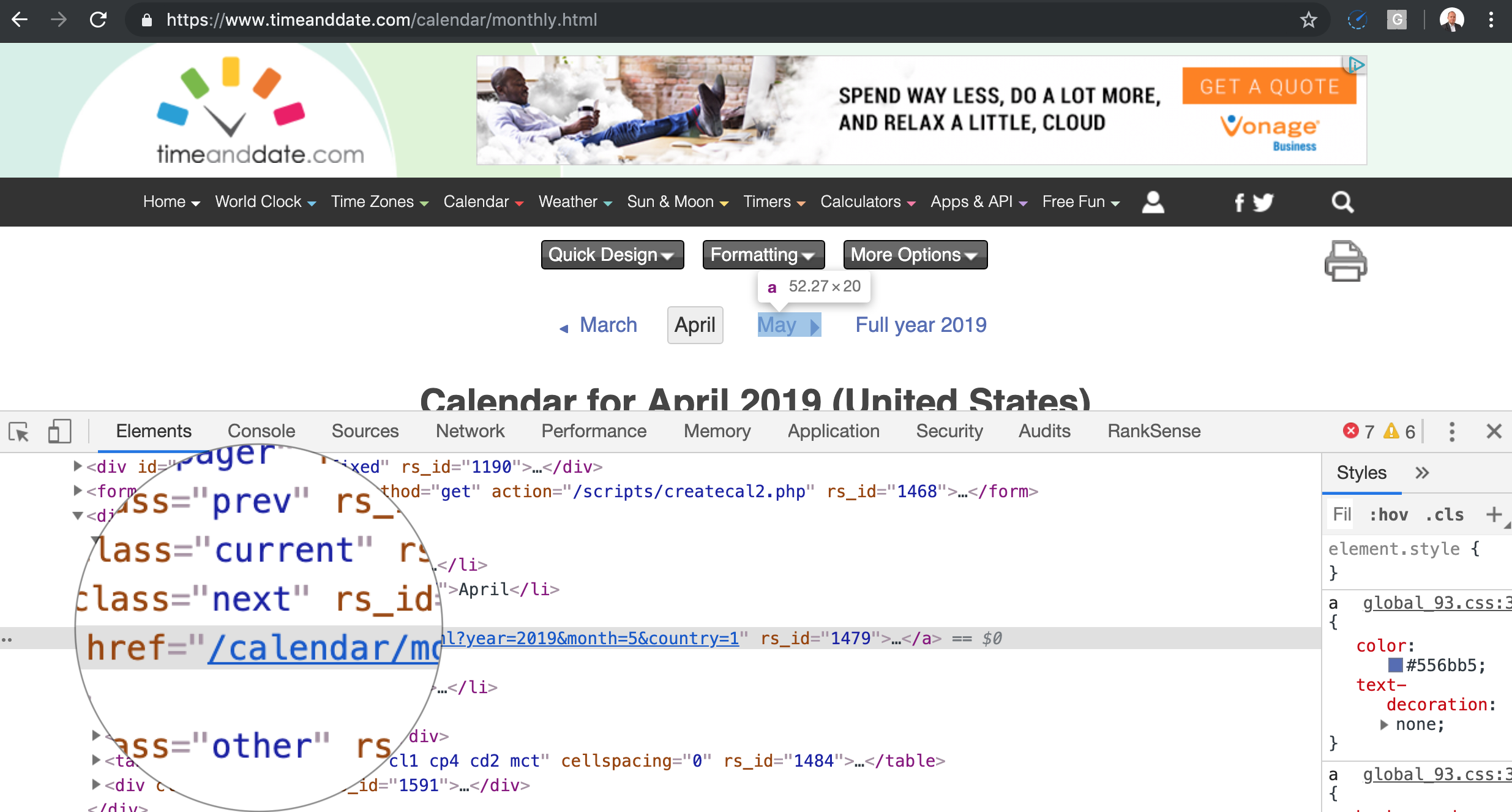
This is probably the easiest crawler trap to understand.
If you place a calendar on a page, even if it is a JavaScript widget, and you let the search engines crawl the next month links, it will never end for obvious reasons.
Writing generalized code to detect this one automatically is particularly challenging. I’m open to any ideas from the community.
How to Catch Crawler Traps Before Releasing Code to Production
Most modern development teams use a technique called continuous integration to automate the delivery of high quality code to production.
Automated tests are a key component of continuous integration workflows and the best place to introduce the scripts we put together in this article to catch traps.
The idea is that once a crawler trap is detected, it would halt the production deployment. You can use the same approach and write tests for many other critical SEO problems.
CircleCI is one of the vendors in this space and below you can see the example output from one of our builds.
How to Diagnose Traps After the Fact
At the moment, the most common approach is to catch the crawler traps after the damage is done. You typically run an SEO spider crawl and if it never ends, you likely got a trap.
Check in Google search using operators like site: and if there are way too many pages indexed you have a trap.
You can also check the Google Search Console URL parameters tool for parameters with an excessive number of monitored URLs.
You will only find many of the traps mentioned here in the server logs by looking for repetitive patterns.
You also find traps when you see a large number of duplicate titles or meta descriptions. Another thing to check is a larger number of internal links that pages that should exist on the site.
Resources to Learn More
Here are some resources I used while researching this article:
- What Crawl Budget Means for Googlebot
- Faceted navigation best (and 5 of the worst) practices by Google
- A field guide to spider traps from Portent
- Crawler traps: how to identify and avoid them from Content King
- What is cache busting
- Scrapy overview
- How to disable jsession ids
- Introduction to CSS selectors
More Resources:
- How Search Engines Crawl & Index: Everything You Need to Know
- Crawl-First SEO: A 12-Step Guide to Follow Before Crawling
- A Guide to Crawling Enterprise Sites Efficiently
Image Credits
All screenshots taken by author, May 2019
Sorry, the comment form is closed at this time.