
25 Oct DataFleets keeps private data useful and useful data private with federated learning and $4.5M seed
As you may already know, there’s a lot of data out there, and some of it could actually be pretty useful. But privacy and security considerations often put strict limitations on how it can be used or analyzed. DataFleets promises a new approach by which databases can be safely accessed and analyzed without the possibility of privacy breaches or abuse — and has raised a $4.5 million seed round to scale it up.
To work with data, you need to have access to it. If you’re a bank, that means transactions and accounts; if you’re a retailer, that means inventories and supply chains, and so on. There are lots of insights and actionable patterns buried in all that data, and it’s the job of data scientists and their ilk to draw them out.
But what if you can’t access the data? After all, there are many industries where it is not advised or even illegal to do so, such as in healthcare. You can’t exactly take a whole hospital’s medical records, give them to a data analysis firm, and say “sift through that and tell me if there’s anything good.” These, like many other data sets, are too private or sensitive to allow anyone unfettered access. The slightest mistake — let alone abuse — could have serious repercussions.
In recent years a few technologies have emerged that allow for something better, though: analyzing data without ever actually exposing it. It sounds impossible, but there are computational techniques for allowing data to be manipulated without the user ever actually having access to any of it. The most widely used one is called homomorphic encryption, which unfortunately produces an enormous, orders-of-magnitude reduction in efficiency — and big data is all about efficiency.
This is where DataFleets steps in. It hasn’t reinvented homomorphic encryption, but has sort of sidestepped it. It uses an approach called federated learning, where instead of bringing the data to the model, they bring the model to the data.
DataFleets integrates with both sides of a secure gap between a private database and people who want to access that data, acting as a trusted agent to shuttle information between them without ever disclosing a single byte of actual raw data.
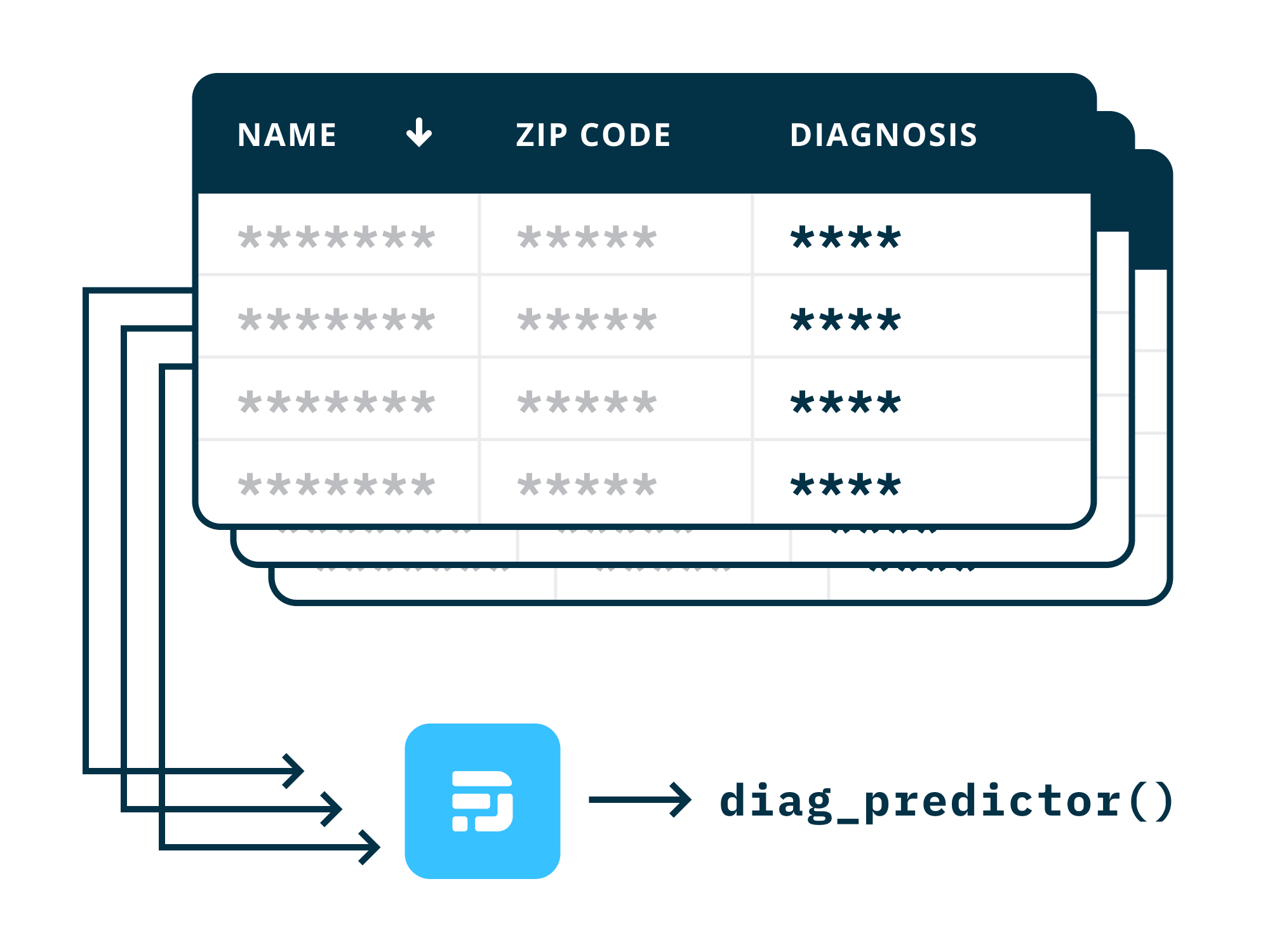
Image Credits: DataFleets
Here’s an example. Say a pharmaceutical company wants to develop a machine-learning model that looks at a patient’s history and predicts whether they’ll have side effects with a new drug. A medical research facility’s private database of patient data is the perfect thing to train it. But access is highly restricted.
The pharma company’s analyst creates a machine-learning training program and drops it into DataFleets, which contracts with both them and the facility. DataFleets translates the model to its own proprietary runtime and distributes it to the servers where the medical data resides; within that sandboxed environment, it grows into a strapping young ML agent, which when finished is translated back into the analyst’s preferred format or platform. The analyst never sees the actual data, but has all the benefits of it.
Screenshot of the DataFleets interface. Look, it’s the applications that are meant to be exciting. Image Credits: DataFleets
It’s simple enough, right? DataFleets acts as a sort of trusted messenger between the platforms, undertaking the analysis on behalf of others and never retaining or transferring any sensitive data.
Plenty of folks are looking into federated learning; the hard part is building out the infrastructure for a wide-ranging enterprise-level service. You need to cover a huge amount of use cases and accept an enormous variety of languages, platforms and techniques, and of course do it all totally securely.
“We pride ourselves on enterprise readiness, with policy management, identity-access management, and our pending SOC 2 certification,” said DataFleets COO and co-founder Nick Elledge. “You can build anything on top of DataFleets and plug in your own tools, which banks and hospitals will tell you was not true of prior privacy software.”
But once federated learning is set up, all of a sudden the benefits are enormous. For instance, one of the big issues today in combating COVID-19 is that hospitals, health authorities, and other organizations around the world are having difficulty, despite their willingness, in securely sharing data relating to the virus.
Everyone wants to share, but who sends whom what, where is it kept, and under whose authority and liability? With old methods, it’s a confusing mess. With homomorphic encryption it’s useful but slow. With federated learning, theoretically, it’s as easy as toggling someone’s access.
Because the data never leaves its “home,” this approach is essentially anonymous and thus highly compliant with regulations like HIPAA and GDPR, another big advantage. Elledge notes: “We’re being used by leading healthcare institutions who recognize that HIPAA doesn’t give them enough protection when they are making a data set available for third parties.”
Of course there are less noble, but no less viable, examples in other industries: Wireless carriers could make subscriber metadata available without selling out individuals; banks could sell consumer data without violating anyone in particular’s privacy; bulky datasets like video can sit where they are instead of being duplicated and maintained at great expense.
The company’s $4.5 million seed round is seemingly evidence of confidence from a variety of investors (as summarized by Elledge): AME Cloud Ventures (Jerry Yang of Yahoo) and Morado Ventures, Lightspeed Venture Partners, Peterson Ventures, Mark Cuban, LG, Marty Chavez (president of the board of overseers of Harvard), Stanford-StartX fund, and three unicorn founders (Rappi, Quora and Lucid).
With only 11 full-time employees DataFleets appears to be doing a lot with very little, and the seed round should enable rapid scaling and maturation of its flagship product. “We’ve had to turn away or postpone new customer demand to focus on our work with our lighthouse customers,” Elledge said. They’ll be hiring engineers in the U.S. and Europe to help launch the planned self-service product next year.
“We’re moving from a data ownership to a data access economy, where information can be useful without transferring ownership,” said Elledge. If his company’s bet is on target, federated learning is likely to be a big part of that going forward.
Sorry, the comment form is closed at this time.