
06 Apr How Bing Ranks Search Results: Core Algorithm & Blue Links via @jasonmbarnard
It is safe to assume that Bing and Google are organized and function on similar lines.
With that in mind, if Google won’t tell us much about how the algorithms function, I figured that asking Bing is the solution if I wanted to better understand.
So that’s what I did.
Below is the first interview in a series of five I did with team leads at Bing.
I’ll publish them all as articles here on Search Engine Journal (as well as the full, uncut conversations on my podcast “With Jason Barnard…” and on the Kalicube.pro YouTube Channel).
First up: Frédéric Dubut, Senior Program Manager Lead, Bing.

The Foundation of Any SERP Is the (10) Blue Links
Dubut states quite categorically that the foundation of every single results page on a modern search engine is the “10 blue links.”
Then, if the query can be directly and usefully addressed with a rich element (SERP feature), the algorithm incorporates the best result in that format.
If multiple rich elements can provide value to the user, then those are also added.
This confirms what Google’s Gary Illyes from Google said last May in Sydney. But with more “gusto.”
If you haven’t already, then before continuing, please do read this detailed explanation of how Darwinism in Search works as explained by Illyes.
Here’s the ultra-simplified explanation:
SERP features are simply an additional format that lives or dies by the evaluation of their usefulness/value for the user as judged by a combination of Darwinistic algorithms.
That’s it. Simple.
That initial article about how Google ranking functions covered a lot of ground, but when I talked to Dubut, he took things further:
- Each candidate set has a dedicated team behind it.
- There is a Whole Page Team that plays the role of “referee” in order to make sure that the page brings “maximum” value to the user.
A Dedicated Team (& Adapted Algo) Behind Each Candidate Set
Each candidate set algorithm works on the same centralized “blue link algorithm” using a modular system that isolates signals (call them factors or features, if you like) and uses different weightings on them.
And each candidate set has a specialized team working on how to:
- Build on top of that algo to best serve the specifics of their feature.
- Generate the best possible results for that set and present it as a candidate for the SERP.
If a candidate set provides a result that is an improvement on the original 10 blue links, it gets a place on the SERP.
Q&A Featured Snippet Algorithm
If we take a featured snippet as an example, being accurate, fresh, and authoritative is more important than having a boatload of links.
Featured snippets (Q&A in Bing-speak) also serves as a great example of answering the query, but more efficiently – for the user, that is an obvious and immediate improvement on a blue link.
Anecdotally, the Q&A team is in the office next door to the blue links team.
Part 3 of this series is the interview with Ali Alvi who leads the Q&A team. It’s the longest of the series and is wildly interesting.
One fact that sticks out in my mind is that he runs the team that generates the descriptions for the blue link results.
And when you consider that with Fabrice Canel’s explanation in Part 2 of this series about the annotations he adds when indexing / storing the pages they crawl, all of this starts to comfortably fit together.
Multimedia Algo
Videos and images are other fairly easy-to-grasp examples of rich elements bringing more value than the blue links to the user for certain intents – most obviously any query that contains the word “image” or “video” but also pretty much any query around pop stars or visual artists.
Interestingly, though, both video and image candidate sets are run by the same team – Multimedia.
Part 4 of this series is the interview with Meenaz Merchant who leads the Multimedia team, which provides some really interesting and important insights – not least the importance of authority and trust.
Bing Ads: ‘Just Another Candidate Set’
Once someone explains the idea of candidate sets competing for a place on the SERP, the next obvious question is:
What about ads?
They are, indeed, simply another candidate set.
If the most relevant ad brings value to the user, then it has a “right” to some space on that SERP.
And the key principle for the ad is that Bing still wants to satisfy users.
In order to retain their audience, Bing has to ensure that they show ads when the content behind that ad, that the user consumes once they click on it, is going to satisfy their query.
So ads are simply another candidate set that expands options on the SERP with a team behind it.
But, as with the rest, the Whole Page algo makes the final decision.
Finding that delicate balance between income for the company with serving the user.
Get that wrong and things would go south very fast.
Google might have over 90% market share.
But too many ads that don’t serve could potentially spell disaster, even with that dominance.
That said, ads remain a special case.
Whatever Google and Bing say, it is obvious that they will carry a certain level of self-serving commercial bias.
But when seen from a macro viewpoint, I would tend to be less-than-overly-critical and suggest that their long-term survival depends on the algorithms creating a reasonable balance.
The idea that either of these companies will go for short term money-grabbing at the expense of long term doesn’t make business sense.
But more than that – if nobody clicks on the ad, they make no money.
Given the way the SERP is presented then we have a situation whereby the ads have to fill the same rile as the other candidates: give an alternative path or provide the same answer in a format that is attractive to the user.
Making money is therefore all about making sure the ad is attractive as an immediate solution for the user – a truly valid alternative to the blue links or the rich results… and that depends on the capacity of the advertisers to:
- Bid on a query where they actually have the solution.
- Provide ad copy that is useful and valuable to the user.
And if we consider shopping ads as rich elements / SERP features in the same was as video boxes, featured snippets and so one, then we can see that ads will evolve Darwinistically in the years to come.
The Whole Page Team
This is the term that really piqued my interest during the conversation with Dubut.
Darwinism implies that any rich element / SERP feature that wants to appear on a SERP lives and dies by whether they can actually convince the algorithm that they have more value than the blue link.
And that is true to a certain level.
Each “candidate set” generates the best answer it can (video, image, featured snippet, People Also Ask…) and they put in their “bid” – but they’re not the ones deciding if it shows up.
That’s the role of the whole page algorithm.
The Whole page team is a phenomenally important concept and a key discovery.
Part 5 of this series is the interview with Nathan Chalmers who leads the Whole Page team – and he confirms that the whole page algorithm does indeed manage what actually shows.
The SERPs don’t work on pure Darwinistic principles… but Chalmers suggests that my concept of Darwinism in Search a very good way of looking at it. And better still, tells me that they have an algo called Darwin 🙂
And, as one would expect, the whole page algo works around intent. It will weight the results and ensure that rich elements that best serve the intent perform well.
For Beyonce, for example, it’s important to show videos and news because that is what users want.
In a case like this, the 10 blue links don’t matter very much.
And that is an example of where the master / whole page algorithm would heavily influence the final decision of what to show.
Simple Explanation of Machine Learning in the Algorithm(s)
- The human tells the machine which are the factors (he calls them features 🙂 that they think are important, and gives them the rules as to what is considered success and failure.
- The machine is then fed with a vast number of different human-labeled examples of good and bad results for a range of different search queries.
- The machine then figures out the different weights for the features that will provide quality results in any circumstance, whatever the input (ie even for new examples the machine has never seen before).
Dubut suggests that a helpful way to look at this is to see the algorithm as simply a measuring model… It measures success and failure and adapts itself accordingly.
But crucially, humans play a central role.
Machines don’t have free rein – the algorithm is built by humans who (through examples) provide a definition of right and wrong.
It is also humans who create and maintain the platform that defines which features are important… or not.
Machine learning simply balances all the features to best satisfy that human judgment.
The Machine Learning Cycle
This is a continuous process. Bing is continuously giving the algorithms feedback so they can improve themselves.
After step 3 set out above, human judges then assess and label the results.
That data is used by the algo teams to tweak the features and the rules, then the labeled data is fed back to the machine.
The negative feedback is used by the machine to adjust and improve. The positive feedback is a reinforcement for the machine’s learning.
It sounds like learning for all of us.
Bing’s Human Judge Guidelines
Importantly, the human judges’ feedback is structured; not based on human intuition that would vary from judge to judge and make the feedback confusing or contradictory for the machine.
The structure comes in the form of a set of guidelines (equivalent to Google’s Search Quality Guidelines / Quality Rater Guidelines) that ensure consistency, maximize objectivity and give structure to the machines.
That human scoring of the results is constantly being fed back into Bing’s algorithms (see above), allowing the machines to adapt and improve the feature weightings and (hopefully) improve their results over time.
Each team (multimedia, Q&A / Featured Snippet, knowledge panels and so on) have their own panels of human judges and their own guidelines that focus on the requirements of the specific rich element.
That would seem to imply that there are other raters guidelines out there in Google-land, which is intriguing.
It also means (to me, at least) that whoever writes those guidelines has a strong, indirect influence on the relative weightings of the features (factors).
And that those weightings must vary significantly from one rich element to another.
Once again, the Whole Page Team makes an interesting case – their human judges and guidelines have (arguably) the most visible impact front and center.
Blue Links Won’t Die Off Anytime Soon
The rich elements use variants of the core blue link algorithm (in what I understand is a modular fashion), and the 10 blue links are the “initial SERP” that all the other elements aim to “invade” by proving they provide more value than a blue link.
To reiterate (because it’s important), SERPs are systematically built from the 10 blue links up. They are the foundation in every respect.
And that means they aren’t going to die off in the foreseeable future.
The emergence and Darwinistic rise of SERP features (rich elements) has killed off some, but blue links won’t become extinct in the foreseeable future.
Seven and a half blue links per SERP on average is probably about in the correct ballpark.
Dubut suggests that this is a good rule of thumb since the overall aim is to keep the SERPs around the same size.
But the length of the SERP and the number of results is ultimately a decision taken by the Whole Page algorithm (more on that in part #5 of this series).
I’ve been looking for reliable data to confirm this, but none of the tools I have asked so far has been able to fully isolate page #1 and supply exact data for blue links versus rich elements for either Google or Bing.
I did manage to do that for exact match Brand search queries on Google.
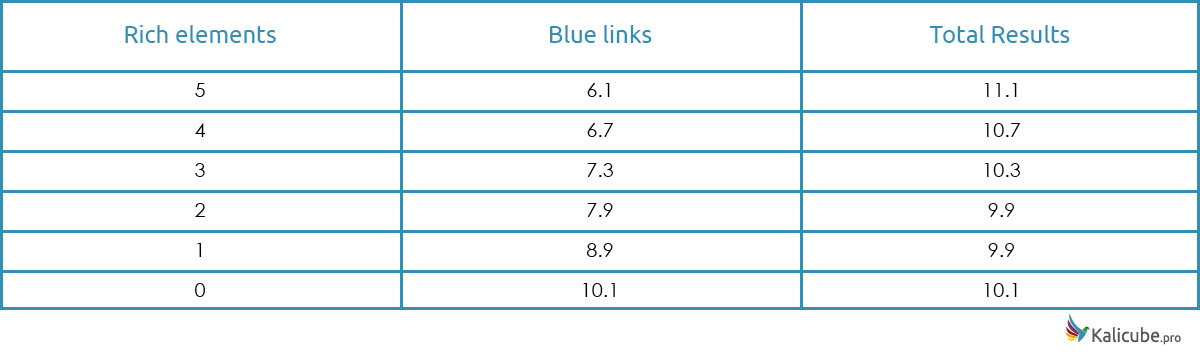
That data (20,000 brands) shows that at Google (sorry, I haven’t been able to track Bing), and specifically for Brand SERPs, there is an average of 8.15 blue links and the average number of rich elements on the left hand side is 2.07.
So rich elements haven’t affected the number of results on page #1 of SERPs very much – although they have got both richer and also slightly longer.
Average results per page are now slightly above 10.
Rich Elements Kill Blue Links on a 1-1 basis
The overall average for my dataset (a little under 20,000 brand SERPs) – 8.15 blue links and 2.07 Rich Elements.
But that data doesn’t tell the whole story.
Something Dubut said towards the end of the interview shed some light and added a delightful caveat that I haven’t yet got detailed data for, but deserves to be investigated further.
So, he is right, the number of results remains pretty stable as rich elements are added on the left hand side.
Rich Elements Do Kill off Blue Links – Sometimes
My initial thought last May when I was writing the Darwinism in Search article was that the increasing presence of rich elements would not only be killing off blue links, but also reducing the number of results on page #1.
The logic is that a rich element not only takes the place of a blue link, but (because of the larger vertical real estate in the case of Twitter boxes, for example) can also kill an additional blue link and the average number of results on page #1 will tend to drop.
Wrong?
Yes.
And No.
Two Types of Query
So, for SERP length, it is useful to look at two distinct macro sets of results – and two rules of thumb.
For unambiguous intent (in this case unambiguous brand names), SERPs have tended to become richer and shorter.
The total number of results tends to drop as the number of rich elements rises.
Since the intent is clear – shorter, richer, more focused results do the job of satisfying their user best.
For ambiguous intent, SERPs have tended to become richer and longer – rich elements tend to add to the page of results and remove little.
Since the intent is unclear – more results with a range of intents will do the job of satisfying their user best.
Why?
With more ambiguous queries, where there are several intents, the engines want to be more comprehensive.
More results and a longer page are the way they offer more diversity and better cover those multiple intents.
Dubut and Chalmers both confirm this to be true. I am sure data will back this up – any platforms who want to make that analysis with me are welcome. 🙂
And a nice number to end with – the overall average number of results on Page 1 remains at 10 (for Brand SERPs, at least).
To Be Continued…
The Bing Series (April 2020)
- How Ranking Works at Bing – Frédéric Dubut, Senior Program Manager Lead, Bing
- Discovering, Crawling, Extracting and Indexing at Bing – Fabrice Canel Principal Program Manager, Bing
- How the Q&A / Featured Snippet Algorithm Works – Ali Alvi, Principal Lead Program Manager AI Products, Bing
- How the Image and Video Algorithm Works – Meenaz Merchant, Principal Program Manager Lead, AI and Research, Bing
- How the Whole Page Algorithm Works – Nathan Chalmers, Program Manager, Search Relevance Team, Bing
More Resources:
- SEO in 2020: Going Beyond Google
- Why & How Bing Plans to Improve Its Crawler, Bingbot
- How to Get Organic Traffic That Isn’t From Google
Image Credits
Featured & In-Post Images: Kalicube.pro
Sorry, the comment form is closed at this time.